News and Events
CNetS hosts several events including talks, colloquia, and a reading group. Anyone is welcome to attend all CNetS events.
No Results Found
Sorry, but nothing matched your search terms. Please try again with different keywords.
-

Jina Lee Talk
May 30, 2025 12pm EDT Luddy AI 2005 Speaker: Jina Lee Title: Selective Recognition: Gendered Recognition of Different Types of Scientific Novelty Abstract: Gender disparities in scientific recognition are not uniform but vary systematically across types of novelty. This study introduces the concept of “selective recognition” to explain how gender shapes whose work is acknowledged as novel and in w…
-

Menczer AAAS Fellow
The American Association for the Advancement of Science, one of the world’s largest general scientific societies and publisher of the Science family of journals, named Filippo Menczer to its 2024 fellows’ class, a lifetime honor within the scientific community. Menczer is among 471 scientists, engineers and innovators who have been elected for their scientifically and socially distinguished achiev…
-

Seungwoong Ha Talk
Seungwoong Ha November 19, 2024 1:00pm Luddy Center for Artificial Intelligence, Room 2005 Zoom: https://iu.zoom.us/j/89107137699 Title: Dynamics of Collective Minds: A Computational Model of news-comment Dynamics" Abstract: In an online community, many of the community users collectively consist of a unique set of interests and beliefs, which can be expressed as a 'collective mind' of the communi…
-

Selena Wang Talk
Speaker: Selena Wang March 12, 2025 3pm Luddy AI 2005 Zoom: https://iu.zoom.us/j/89307757306 Title: Neuroimaging connectivity analysis needs network science for brain-behavior linking Abstract: The brain is comprised of interacting neurons, and its complexity poses significant challenges for researchers to understand its structure, function, and dynamics. Statistical network analysis (SNA), a coll…
-

Postdoctoral Fellow Opening - Apply by November 1
The Observatory on Social Media (OSoMe) at Indiana University - Bloomington invites applications for a Postdoctoral Fellow (one year term with expected renewals for up to 3 years). The Postdoctoral Fellow will work closely with Yong-Yeol “YY” Ahn and other researchers at the Observatory on modeling the knowledge space and the role of scientific funding in technological advancement. This position w…
-
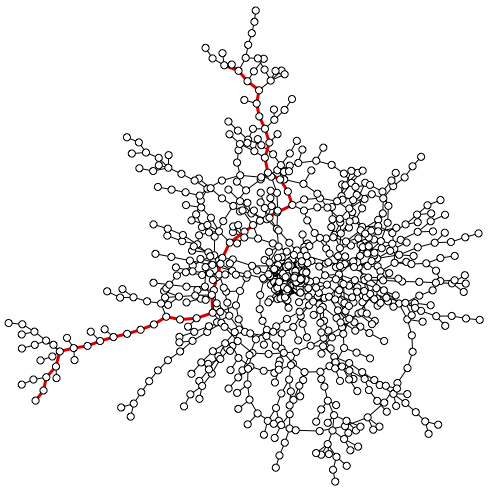
New paper in PRL on shortest-path percolation
CNetS Ph.D. student Minsuk Kim and faculty Filippo Radicchi have introduced a new bond-percolation model aimed at describing the consumption, and eventual exhaustion, of resources in transportation networks. Results of this research have been reported in a paper just published in Physical Review Letters. See also Luddy's press release.
-

Radicchi appointed as Associate Editor for Physical Review E
CNetS faculty Filippo Radicchi assumed the position of Associate Editor at Physical Review E, the flagship journal for Complex Networks and Systems research. Radicchi will handle manuscripts submitted to the journal’s “Networks and Complex Systems” section. See also Luddy's press release and the announcement by Physical Review E.
-

CNetS researchers reach finals of the Prosocial Ranking Challenge
We are developing a “bridging” algorithm to rerank social media feeds, aiming to foster civil discussions and appeal to a diverse audience, thus creating a more positive and inclusive online environment. We accomplish this by promoting content that elicits diverse and positive responses while demoting toxic content and content eliciting toxic responses. Our algorithm achieves this by evaluating po…
-

OSoMe and CNetS researchers to present 26 papers at summer conferences
We’re excited to announce that researchers at the Observatory on Social Media and the Center for Complex Networks and Systems Research will present 26 papers at various conferences over the summer. Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) Zoher Kachwala, Jisun An, Haewoon Kwak, Filippo Menczer: REMATCH: Robust and effici…
-
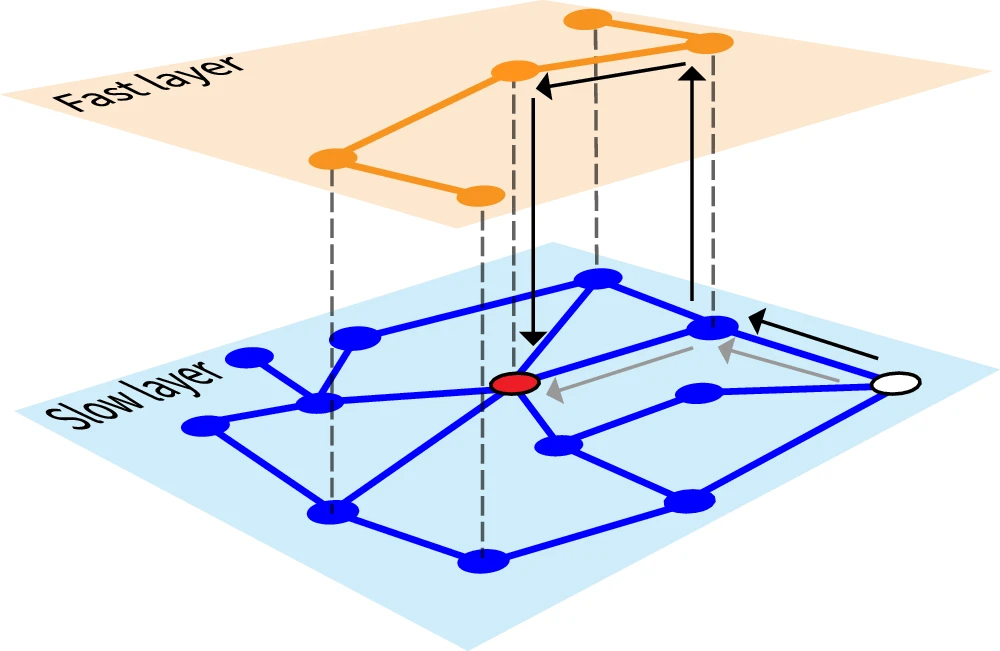
New paper in Nature Communications on optimal transport networks
CNetS faculty Filippo Radicchi and Santo Fortunato, along with collaborators Siddharth Patwardhan, Şirag Erkol and Marc Barthelemy, have developed theoretical and computational frameworks to study the shape of multilayer transport networks within cities. They have found that, when optimized to reduce transit time to a central node, such networks undergo sharp phase transitions from symmetric to as…
-
Talk by Nicholas LaRacuente
This talk has been canceled and will be rescheduled for Fall 2024. When: Canceled Where: Canceled Speaker: Nicholas LaRacuente Title: Learning Across Complex Systems to Use Small, Noisy Datasets Effectively Abstract: There is often a gap between how explainable a complex, non-equilibrated system appears and how well plausible models verifiably explain or predict it. This situation is common for e…
-
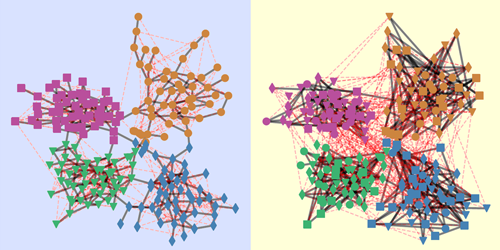
New paper in PRX on control of epidemic spreading
CNetS faculty Filippo Radicchi and Santo Fortunato, along with graduate students Siddharth Patwardhan and Varun Rao, have found that, in order to limit the spreading of epidemics, it is advantageous to act on the composition of social groups. Specifically, since contact networks consists of different levels (school, work, family, etc.), groups of individuals should be highly overlapping between la…
-
Talk by Luca Luceri
When: October 4, 2023, 12:00pm-1:00pm EDT Where: Luddy Center for Artificial Intelligence 2005 Register: https://iu.zoom.us/meeting/register/tZIldu6spzojEte0cTVN4D1ZD_pZzmBDeBAv Speaker: Luca Luceri Title: AI-Driven Approaches for Countering Influence Campaigns in Socio-Technical Systems Abstract: The proliferation of online platforms and social media has sparked a surge in information operations …
-

Talk by Marios Papachristou
When: September 11, 2023, 1:00pm EDT Where: Luddy Center for Artificial Intelligence 2005 Zoom link: https://iu.zoom.us/webinar/89107137699 Speaker: Marios Papachristou Title: Resource Allocation in a Financial Contagion Environment Abstract: The pandemic has spread uncertainty among financial entities that experience income shocks. A policy framework is stimulus checks, i.e. cash injections into…
-

Talk by Yu Tian
When: September 15, 2023, 11:30am EDT Where: Luddy Center for Artificial Intelligence 2005 (remote talk-feel free to attend with others) Zoom link: https://iu.zoom.us/webinar/89107137699 Speaker: Yu Tian Title: Structural Balance and Random Walks on Complex Networks with Complex Weights Abstract: Complex numbers define the relationship between entities in many situations. A canonical example would…
-

Anatomy of an AI-powered malicious social botnet
A preprint of the paper titled “Anatomy of an AI-powered malicious social botnet” by Yang and Menczer was posted on arXiv. Concerns have been raised that large language models (LLMs) could be utilized to produce fake content with a deceptive intention, although evidence thus far remains anecdotal. This paper presents a case study about a coordinated inauthentic network of over a thousand fa…
-
Talk by Diego R. Amancio
When: June 23, 2023 2pm EDT Where: Luddy Center for Artificial Intelligence 2005 (in-person) Speaker: Diego R. Amancio Title: Examining the Influence of top collaborators on authors' metrics Abstract: Science has become more collaborative over the past years. Although various aspects of scientific collaboration have been investigated, our study specifically focused on examining the influence of th…
-
Two papers got accepted for ACM WebSci'23
Two of our latest works got accepted for the 15th ACM Web Science Conference (WebSci'23)! Web Science is an interdisciplinary field to study socio-technical systems, particularly on the web, and ACM WebSci is the premier conference for Web Science research. "Political Honeymoon Effect on Social Media: Characterizing Social Media Reaction to the Changes of Prime Minister in Japan" by Kunihiro Miy…
-

OSoMe, IUNI, and CNetS to present 57 papers at upcoming conferences
We’re excited to announce that researchers at the Observatory on Social Media, the IU Network Science Institute, and the Center for Complex Networks and Systems Research will present 57 papers at various conferences over the summer. Network Science Conference (NetSci) Oral presentations Sadamori Kojaku, Clara Boothby, Filipi Silva, Attila Varga, Xiaoran Yan, Stasa Milojevic…
-

Talk by Ankur Mani
When: April 03, 2023 12pm EST Where: Luddy Center for Artificial Intelligence (LU2005) Speaker: Ankur Mani Title: Investigating Churn in Online Wellness Programs: Evidence from a U.S. Online Social Network Abstract: Online wellness activity platforms increasingly utilize wellness programs and social support to motivate healthy activities and improve user engagement. However, many wellness program…
-

Talk by Jonas Juul
When: November 11, 2022 12pm EST Where: Remote Talk Zoom link: https://iu.zoom.us/j/89873992894?pwd=QmxmaXZaakNFSUpnQm1jT1I3T1ZOZz09 Recording: Jonas Juul Cascades Talk Speaker: Jonas Juul Title: Harder, better, faster, stronger cascades -- or simply larger? Abstract: Do some types of online content spread faster or further than others? In recent years, many studies have sought answers to su…
-

Fortunato elected Fellow of the American Physical Society
Santo Fortunato has been elected Fellow of the American Physical Society (APS) for foundational contributions to the statistical physics of complex networks, and particularly to the study of community detection in networks and applications to social and scientific networks. The Fellowship is awarded annually to no more than one half of one percent of members of the APS for exceptional contributio…
-

New paper in Nature Physics
In 2002 the paper Community structure in social and biological networks, by Michelle Girvan and Mark E. J. Newman, marked the beginning of network community detection, possibly the most popular topic in network science, which tackles the problem of automatically discovering communities — groups of nodes of the network that are strongly connected or that share similar features or roles. Twenty yea…
-
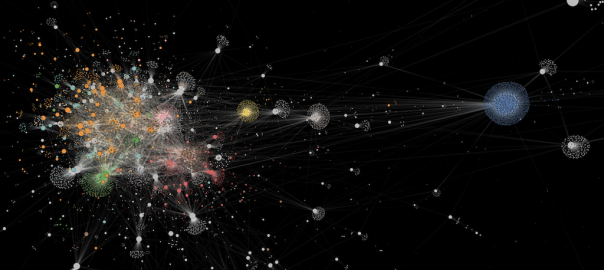
New network visualization tool maps information spread
Today the Observatory on Social Media and CNetS launched a revamped research tool to give journalists, other researchers, and the public a broad view of what's happening on social media. The tool helps overcome some of the biggest challenges of interpreting information flow online, which is often difficult to understand because it's so fast-paced and experienced from the perspective of an i…
-

Fortunato elected Fellow of the Network Science Society
Santo Fortunato has been elected Fellow of the Network Science Society (NSS) for seminal work in network community structure leading to advances in multiresolution approaches and validation, and for contributions to disseminating network science. The Fellowship is awarded annually to members of the community for their exceptional lifelong individual contributions to any area of network science re…
-

Fortunato receives Zachary's Karate Club Award
Santo Fortunato is the 21st recipient of the Zachary's Karate Club Award, for being the first to mention the famous social network at NetSci 2022, during the satellite workshop Communities in Networks. Fortunato received the singular trophy from Jesus Arroyo Relion. He is the third member of CNetS to receive this award, after YY Ahn and Filippo Radicchi.
-
Talk by Brett Buttliere
When: January 19, 2022, 2:00pm Where: Luddy Center for Artificial Intelligence (2044) Zoom link: https://iu.zoom.us/j/89107137699 Speaker: Brett Buttliere Title: Psychology and cognitive conflict in the diffusion of scientific information. Abstract: The talk will focus on the psychology of scientist in both doing science and diffusing science, focusing in particular on the role of cognitive confl…
-

We're moving and hiring!
We have two big announcements! First, CNetS (along with IUNI and OSoMe) is moving to the new Luddy Center for Artificial Intelligence. Second, we have a new tenure-track assistant professor position in Artificial Intelligence and Network Science. We welcome any candidates who study AI, complex systems, and network science (all broadly defined). Potential research areas include, but are not …
-

Talk by Francesco Pierri
When: October 15, 2021, 12:00pm Where: Luddy 1106 (Dorsey Learning Hall) Zoom link: https://iu.zoom.us/j/89107137699 Speaker: Francesco Pierri Title: Characterization and detection of disinformation spreading in online social networks Abstract: Online social media expose us to a variety of false and misleading information which erodes public trust towards institutions, with severe backlashes i…
-
New grant on optimization problems in complex networks
The US Air Force Office of Scientific Research has awarded the grant Algorithmic and theoretical approaches to optimization problems on complex networks to CNetS faculty Filippo Radicchi. The project will study different classes of optimization problems (OPs) on complex networks, including optimal percolation, optimal sampling, optimal navigation, and optimal seeding. The research will address …
-
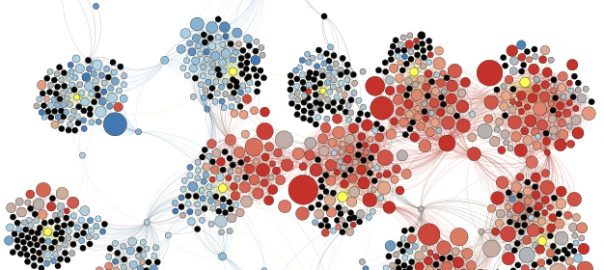
Probing political bias on Twitter with drifter bots
Our latest paper "Neutral bots probe political bias on social media" by Wen Chen, Diogo Pacheco, Kai-Cheng Yang & Fil Menczer just came out in Nature Communications. We find strong evidence of political bias on Twitter, but not as many think: (1) it is conservative rather than liberal bias, and (2) it results from user interactions (and abuse) rather than platform algorithms. We tracked…
-
ICWSM Test of Time Award
Our 2011 paper Political Polarization on Twitter was recognized at the 2021 AAAI International Conference on Web and Social Media (ICWSM) with the Test of Time Award. First author Mike Conover, who was then a PhD student and is now Director of Machine Learning Engineering at Workday, accepted the award at a ceremony at the end of the ICWSM conference. Other authors are Jacob Ratkiewicz (now a Tec…
-
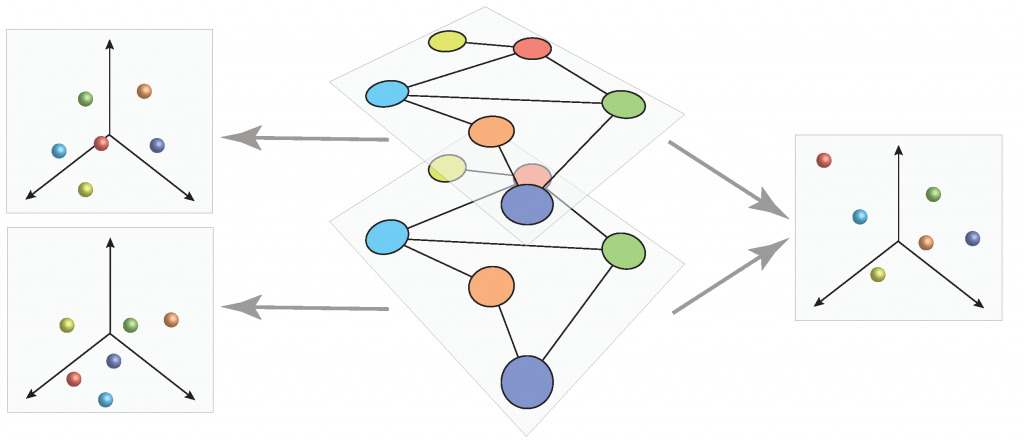
New grant on AI and multilayer networks
The Army Research Office has awarded the grant Multilayer network embeddings and applications to real-world problems to CNetS faculty Santo Fortunato and Filippo Radicchi. The project lies at the interface between artificial intelligence and network science and aims at developing embeddings of multilayer networks in vector space. While graph embeddings have become very popular over the past decad…
-
Talk by Chris Connell
When: Friday, May 14, 2021 Where: https://iu.zoom.us/j/87346711649 Speaker: Chris Connell Title: The DynACPD network embedding algorithm for prediction tasks on dynamic networks Abstract: Classical network embeddings create a low dimensional representation of the learned relationships between features across nodes. Such embeddings are important for tasks such as link prediction and node classifica…
-

Distinguished Master’s Thesis Award
CNetS alumnus Mihai Avram is the recipient of the 2020 Indiana University Distinguished Master’s Thesis Award for his work on Hoaxy and Fakey: Tools to Analyze and Mitigate the Spread of Misinformation in Social Media. This award recognizes a "truly outstanding" Master's thesis based on criteria such as originality, documentation, significance, accuracy, organization, and style. Some of the findin…
-
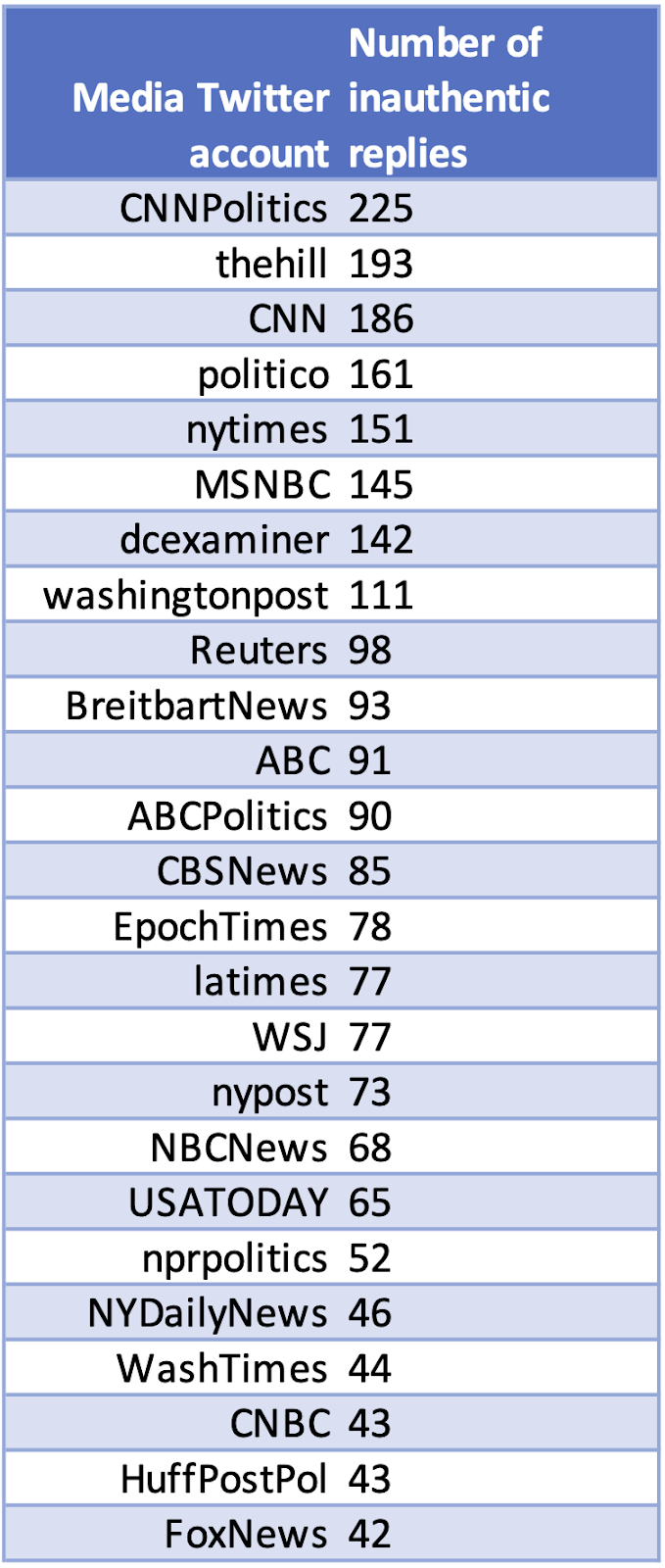
Evidence of a coordinated network amplifying inauthentic narratives in the 2020 US election
On 15 September 2020, The Washington Post published an article by Isaac Stanley-Becker titled “Pro-Trump youth group enlists teens in secretive campaign likened to a ‘troll farm,’ prompting rebuke by Facebook and Twitter.” The article reported on a network of accounts run by teenagers in Phoenix, who were coordinated and paid by an affiliate of conservative youth organization Turning Point USA. T…
-
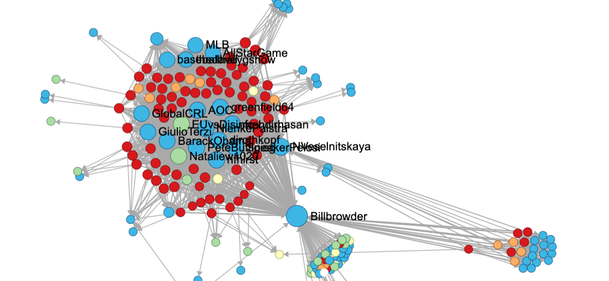
UPDATE: BotSlayer tool to expose disinformation networks
We are excited to announce the new v.1.3 of BotSlayer, our OSoMe cloud tool that lets journalists, researchers, citizens, & civil society organizations track narratives and detect potentially coordinated inauthentic information networks on Twitter in real-time. Improvements and new features include better stability, a new alert system, a Mac installer, and many additions to the interface. Thi…
-

Botometer V4
In September 2020, we are introducing a major upgrade for Botometer. This post explains the changes and motivations behind them. Introducing Botometer V4 We are replacing the Botometer V3 model that has been running for the past two years with a new V4 model, hoping to provide more accurate and transparent results for our users. Botometer is a supervised machine learning tool, which means it lear…
-

Knight Fellows
Indiana University’s Observatory on Social Media, funded in part last year with a $3 million grant from the John S. and James L. Knight Foundation, has named two new Knight Fellows. Matthew DeVerna and Harry Yaojun Yan will help advance the center’s ongoing investigations into how information and misinformation spread online. The Observatory on Social Media, or OSoMe (pronounced “awesome”), is a c…
-

CNetS @ NetSci 2020
CNetS students, postdocs, and faculty members will give 7 regular talks and present 13 posters at NetSci 2020, held online this year due to COVID-19. Regular talks will cover research on many topics including COVID-19, forecasting social contagion of anti-vax ideas, political bias in social media, coordinated manipulation online, the scientific development of nations, hierarchy in faculty hirin…
-

CNetS @ IC2S2
CNetS students, postdocs, and faculty members will be presenting 12 papers, 7 posters, and a tutorial on OSoMe tools at the 2000 International Conference on Computational Social Science (IC2S2), held online this year due to COVID-19. In addition, Fil Menczer will deliver one of the keynotes. Oral presentations will cover research on many topics including social bot detection, political bias in soc…
-
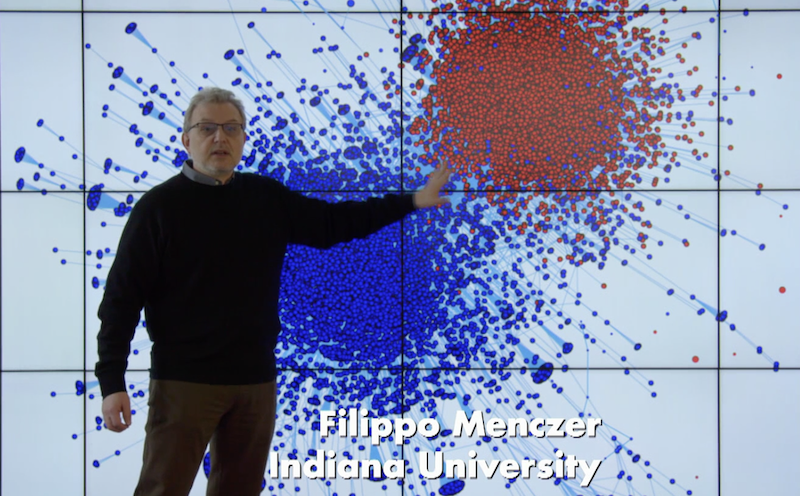
CNetS research featured on PBS
In the groundbreaking new PBS series "NetWorld," Niall Ferguson visits network theorists, social scientists and data analysts (including at CNetS!) to explore the intersection of social media, technology and the spread of cultural movements. Reviewing classic experiments and cutting-edge research, NetWorld demonstrates how human behavior, disruptive technology and profit can energize ideas and co…
-

Hey, I am a distinguished professor!
I am very honored and feel that this is a recognition of years of teamwork with wonderful colleagues and amazing students and postdocs at IU. More...
-

New texbook from CNetS
The book A First Course in Network Science by CNetS faculty members Filippo Menczer and Santo Fortunato and CNetS PhD graduate Clayton A. Davis was recently published by Cambridge University Press. This textbook introduces the basics of network science for a wide range of job sectors from management to marketing, from biology to engineering, and from neuroscience to the social sciences. Extensive …
-
CNetS organizing Summer Institute in Network Science
The Indiana University Network Science Institute (IUNI), jointly with the Network Science Institute at Northeastern University (NetSI) are organizing SINSA 2020, the first Summer Institute in Network Science and its Applications, a two-weeks long school divided into eight teaching modules on major topics of network science, with top instructors, intended for graduate students, practitioners and ea…
-
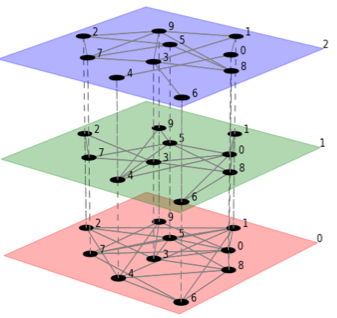
CNetS leading first international exchange program in network science
Schematic example of multilayer network The National Science Foundation has awarded a $1.9 million grant through the new AccelNet program to the Indiana University Network Science Institute (IUNI), to build an international exchange program focused on multilayer networks. Santo Fortunato, CNetS member and IUNI Director, is the PI of this award, jointly with Alessandro Vespignani, representing the …
-
Talk by Jean-Gabriel Young
When: Wednesday, October 2, 2019, 2pm Where: Informatics East, room 322 Speaker: Jean-Gabriel Young Efficient and fully Bayesian inference of complex networks from noisy data Abstract: Rarely do we have access to error-free measurements of networks. Instead, we typically get to observe sequences of states that are, at best, indirect observations of a system's structure. Recent research has led …
-
Talk by Eun Lee
When: Friday, October 4, 2019, 11am Where: Informatics East, room 322 Speaker: Eun Lee Homophily and minority-group size explain perception biases in social networks Abstract: People’s perceptions about the size of minority groups in social networks can be biased, often showing systematic over- or underestimation. These social perception biases are often attributed to biased cognitive or motiv…
-

CNetS faculty organizing Networks 2021
The Indiana University Network Science Institute (IUNI) will be the main organizer of Networks 2021, the largest ever conference in the science of networks. This historical event will be hosted at the Hyatt Regency Washington in Capitol Hill, in Washington DC, on July 6-11, 2021. It will combine the annual meeting of the International Network for Social Network Analysis (Sunbelt XLI), and t…
-
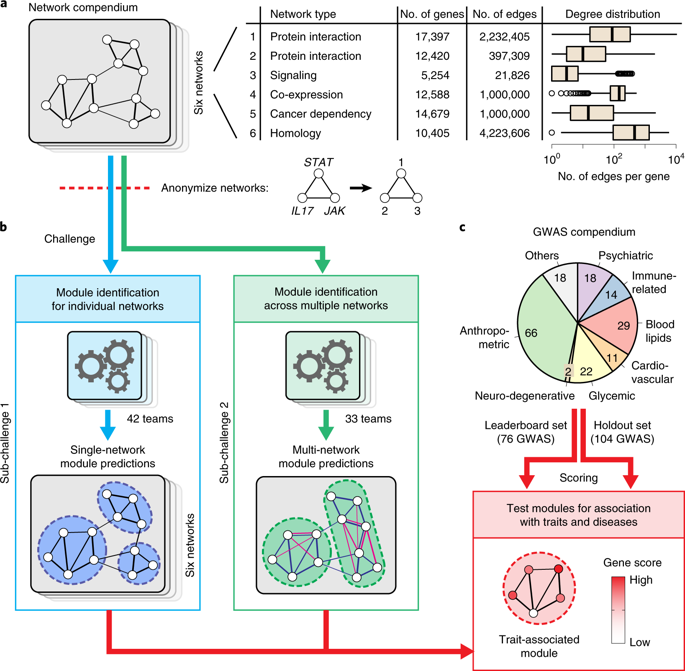
DREAM Challenge paper published in Nature Methods
Structure of the Disease Module Identification DREAM Challenge The outcome of the DREAM Challenge on Disease Module Identification in genetic networks has been reported in a paper published in Nature Methods. Over 400 participants from all around the world have contributed 75 different clustering algorithms to predict disease-relevant modules in diverse gene and protein networks. Participants coul…
-

New $6 million center will investigate media and technology in society
Indiana University will establish a $6 million research center to study the role of media and technology in society. With leadership by CNetS faculty, the Observatory on Social Media will investigate how information and misinformation spread online. It will also provide students, journalists and citizens with resources, data and training to identify and counter attempts to intentionally man…
-
CNetS researchers map global economy
A team of CNetS researchers has created the first global map of labor flow in collaboration with the world’s largest professional social network, LinkedIn. The work is reported in the journal Nature Communications. The study’s lead authors are Jaehyuk Park and Ian Wood, PhD students working with YY Ahn. Wood is currently a software engineer at LinkedIn. Other authors on the study are CNetS …
-

CNetS faculty lead two prestigious DoD Minerva projects on the science of science
Two CNetS teams were awarded prestigious awards from Minerva, a research initiative of the Department of Defense that supports basic social science research focusing on topics of particular relevance to U.S. national security. One of the two awards will develop Science Genome, a new quantitative framework to investigate science of science using representation learning and graph embedding. T…
-
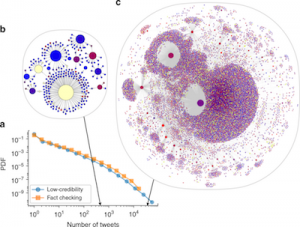
Twitter bots play disproportionate role spreading misinformation
UPDATE: This paper is ranked #3 most read among all articles published by Nature Communications in 2018 Analysis by CNetS researchers of information shared on Twitter during the 2016 U.S. presidential election has found that social bots played a disproportionate role in spreading misinformation online. The study, published in the journal Nature Communications, analyzed 14 million messages …
-

Congrats Dr. Clayton Davis!
Congratulations to Clayton A. Davis, who successfully defended his PhD dissertation titled "Collect, Count, and Compare": Expanding Access and Scope of Social Media Analysis. Dr. Davis' work explored ways to facilitate research using massive social data through tools that are friendly for non-technical users, robust to manipulation by social bots, and that offer strict anonymity guarantees.…
-

Congratulations to Dr. Rion Brattig Correia!
Luis Rocha and Rion Brattig Correia Congratulations to Rion Correia, who successfully defended his PhD dissertation on Prediction of Drug Interaction and Adverse Reactions, with data from Electronic Health Records, Clinical Reporting, Scientific Literature, and Social Media, using Complexity Science Methods. Dr. Correia's research used network science, machine learning, and data science to uncove…
-

Congratulations to Dr. Dimitar Nikolov
Congratulations to Dimitar Nikolov, who successfully defended his PhD dissertation on Information Exposure Biases in Online Behaviors. Dr. Nikolov's research explored the unintentional biases introduced by filtering, ranking, and recommendation algorithms that mediate our online consumption of information. His findings show that our reliance on modern online technologies limits exposure to diver…
-
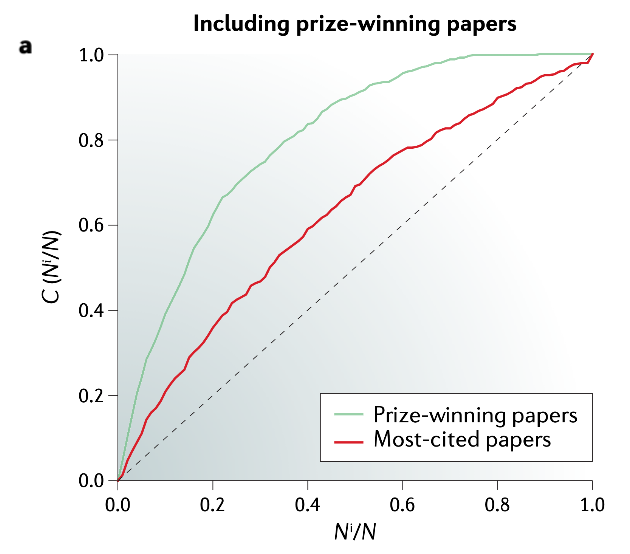
New paper on Nobel Laureates in Nature Reviews Physics
A new paper published in Nature Reviews Physics by Professor Santo Fortunato and colleagues from Northwestern University features a detailed analysis of the careers of Nobel Prize Laureates. They found that the prize- winning works in the three main science categories (physics, chemistry and medicine) tend to occur early in the career of the Laureate. Cumulative distributions of the relative posi…
-
CNetS article wins PNAS Cozzarelli prize
Alexander T. J. Barron, a PhD candidate in CNetS, and co-authors are recipients of the 2018 Cozzarelli Prize in Behavioral and Social Sciences for their paper, Individuals, institutions, and innovation in the debates of the French Revolution. Every year, six of these awards are given to PNAS publications according to their “outstanding scientific quality and originality.” Each of the papers…
-

Research Award recognizes NSF Research Traineeship on Complex Networks and Systems
Luis Rocha, Katy Borner, Paul Macklin and other faculty from the School of Informatics, Computing and Engineering (SICE) were the awardees of the 2019 SICE Research Awards. Luis Rocha received the award in recognition of the NSF Research Traineeship (NRT) on Complex Networks and Systems and two NIH NLM R01 grants. The awards were handed by SICE Dean Raj Acharya and Associate Dean for Research Kay …
-

Talk by Jinhyuk Yun
When: Tuesday, May 7, 2019, 2:00 pm Where: Informatics West, Room 232 Speaker: Jinhyuk Yun Inequality in the formation of collaborative knowledge - the case of Wikipedia See: J. Yun et al., Nature Human Behaviour 3, 155 (2019) Abstract: Wikipedia and its sibling projects have served as a representative medium of worldwide knowledge market to share individuals’ knowledge in the information age. …
-

AI, Society and Organizations
On the 7th of March 2019, CNETS Professor Luis Rocha will participate in a panel organized by Nova SBE’s Executive Education, Instituto Gulbenkian da Ciência and ISI Foundation with the theme of AI, society and organisations: experiences from applied projects in governments, companies and NGO’s, where the role of data science in today’s world will be discussed. Other guest speakers, include Rayi…
-

Charting interdisciplinary research opportunities between data and life sciences
CNetS Professor Luis Rocha, together with ISI foundation (ISI) scientist Ciro Cattuto organize a workshop with the Instituto Gulbenkian de Ciencia to explore synergies between data/computational science and the life, health and social sciences. More information on the workshop event page.
-

CNeTS researcher provides expertise on misinformation battle at AAAS conference
Filippo Menczer, a professor of computer science and informatics at CNetS, appeared on a panel of experts to discuss the emergence and dissemination of misinformation, and how it threatens society at the annual meeting of American Association for the Advancement of Science in Washington, D.C., Feb. 15. Menczer was a part of a three-person panel and presented a talk, “Eight Ways Social Media Makes…
-
Talk by Sadamori Kojaku
When: Tuesday, February 5, 2019, 12:30 pm Where: Informatics West, Room 232 Speaker: Sadamori Kojaku Multiple Core-Periphery Pairs in Networks Abstract: Networks with core-periphery structure comprise core and peripheral nodes, where core nodes are densely interconnected with each other while peripheral nodes are sparsely interconnected with each other. Many empirical networks are shown to be co…
-
Talk by Didier A. Vega-Oliveros
When: Friday, February 8, 2019, 2:00 pm Where: Informatics West, Room 232 Speaker: Didier A. Vega-Oliveros Complex Networks' Approaches for Analyzing Climate (and Other Spatiotemporal) Data Abstract: Complex network theory has helped to identify valuable information in many domains, where systems are complex with non-trivial connections and properties. In this way, understanding how the netwo…
-
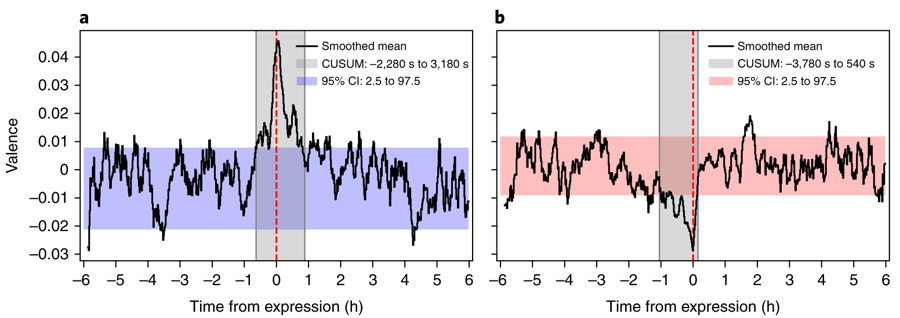
CNetS social media study shows how affect labeling can help moderate emotions
Your mother always told you that if something was bothering you, you should talk about it. It would make you feel better. Turns out she was right, and researchers at the School of Informatics, Computing, and Engineering have the science to prove it. Johan Bollen, a professor of informatics and computing, leads a team that analyzed the Twitter feeds of tens of thousands of users to study how emoti…
-

CNetS team awarded NIH grant to improve chronic-disease management with Data and Network Science
The National Institutes of Health, under the National Library of Medicine’s program on data science research, awarded a $1.55 million grant to an interdisciplinary team lead by Luis Rocha, a professor of informatics, member of CNETS and the director of the NSF-NRT complex networks & systems program at the School of Informatics, Computing, and Engineering. The four-year project, a collaboration…
-

CNetS grad honored with 2018 University Distinguished Ph.D. Dissertation Award
Onur Varol, a postdoctoral research associate at Northeastern University who earned his Ph.D. in Informatics from CNetS, has been honored with the University Distinguished Ph.D. Dissertation Award for 2018, which is the highest honor for research Indiana University bestows on its graduate students. “I am extremely happy to receive this award,” Varol said. “I would like to especially thank m…
-

CNetS grad combats the spread of fake news with new mobile app
The spread of fake news is no game, but to recent CNetS graduate Mihai Avram, a game just might be the solution. As a graduate student in CNetS, Avram developed a mobile app called Fakey to help combat the spread of fake news on social media. It is available to download for both Android and iOS. The news literacy game places users in a simulated social media environment where they can share, "like…
-

3 new tools to study and counter online disinformation
Researchers at CNetS, IUNI, and the Indiana University Observatory on Social Media have launched upgrades to two tools playing a major role in countering the spread of misinformation online: Hoaxy and Botometer. A third tool Fakey -- an educational game designed to make people smarter news consumers -- also launches with the upgrades. Hoaxy is a search engine that shows users how stories from low…
-

The science of fake news
The indictment of 13 Russians in the operation of a "troll farm" that spread false information related to the 2016 U.S. presidential election has renewed the spotlight on the power of "fake news" to influence public opinion. Now, an Indiana University faculty member who studies the spread of misinformation online is joining prominent legal scholars, social scientists and researchers in a global "c…
-
CNetS in Science
The manifesto of science of science has been published in Science magazine. This is a team effort involving 14 coauthors, three of whom are members of our center: Santo Fortunato (first and corresponding author), Staša Milojević and Filippo Radicchi. The team includes superstars in the field of complex systems like Albert-László Barabási, Dirk Helbing, Alessandro Vespignani, and Brian Uzzi. The pa…
-
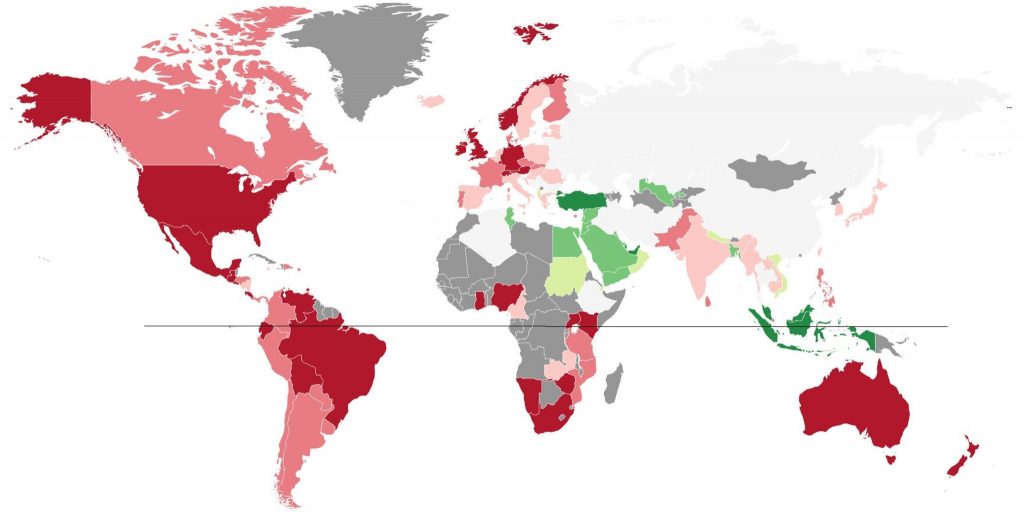
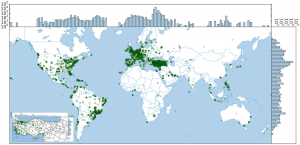
Study finds online interest in sex rises at Christmas, with more births nine months later
World Map Categorized by Sex Search Patterns First global analysis of human birth-rate cycles reveals that post-holiday 'baby boom' persists across cultures, hemispheres. CNetS PhD student Ian Wood and Professors Luis Rocha and Johan Bollen, in collaboration with Joana Sá, used data science and computational social science methods to demonstrate that "Human Sexual Cycles are Driven by C…
-
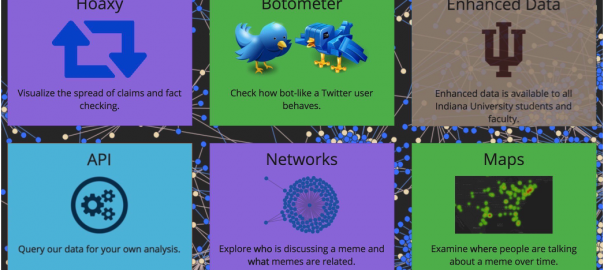
OSoMe for all IU researchers
Thanks to support from the Indiana University Network Science Institute (IUNI) and Digital Science Center (DSC), the full content of the Twitter data repository from the Observatory on Social Media (OSoMe) is now available to all IU researchers. Many tools to detect social bots, study the spread of fake news, visualize meme diffusion networks, trends, and maps, as well as APIs to access thi…
-
DARPA grant to study information spread
Fil Menczer, professor of computer science and informatics at the School of Informatics, Computing, and Engineering, is part of a group that has been awarded a $1.2 million grant from the Defense Advanced Research Projects Agency (DARPA) to study how and at what rate information spreads in a global information environment. The project, COSINE: Cognitive Online Simulation of Information Network Env…
-

CNETS professors create complex systems on the dance floor
E-Trash/Rocha and DJ Angst/Bollen performing at the Riot Bootique "On the last Friday of each month, instead of heading home to their families after the weekly School of Informatics, Computing and Engineering faculty meeting, professors Luis Rocha and Johan Bollen head to the Root Cellar Lounge and become DJ E-Trash and DJ Angst. [...] Both Bollen and Rocha are considered experts in the…
-

CNETS PhD Program central in new $3 million NSF Training Grant
The National Science Foundation has awarded nearly $3 million to train future research leaders in Complex Networks and Systems, via the PhD Program established by CNETS faculty. The highly selective grant from the NSF's Research Traineeship Award will create a dual Ph.D. program at Indiana University to train graduate students to be proficient in both a specific discipline, such as psychology or p…
-

New PhD Graduate
Congratulations to Prashant Shiralkar for successfully defending his dissertation entitled "Computational Fact Checking by Mining Knowledge Graphs" on August 18th 2017, supervised by Filippo Menczer. Prashant completed a PhD degree in Computer Science and has accepted a position at Amazon.
-

Knight Prototype Fund grant for Hoaxy Botornot
A project from NaN and IUNI was among 20 selected (out of over 800 applications) to address the spread of misinformation with support from the Knight Prototype Fund. Led by Fil Menczer, Giovanni Ciampaglia, Alessandro Flammini and Val Pentchev, the project will integrate the Hoaxy and Botometer tools and uncover attempts to use Internet bots to boost the spread of misinformation and shape …
-

NetSci 2017
NetSci, the flagship annual conference of the Network Science Society, was hosted this year by the Indiana University Network Science Institute (IUNI) with Filippo Menczer and Olaf Sporns serving as general co-chairs. NetSci 2017 was the largest meeting to date, since the conference started at IU Bloomington in 2006. NetSci fosters interdisciplinary communication and collaboration in networ…
-

Clayton Davis awarded AI prize
Every year the Informatics Department awards a prize to an Associate Instructor (AI) who has excelled at teaching and service. For the 2016-2017 academic year, CNetS PhD candidate Clayton A. Davis was singled out among a crowd of outstanding nominees as being particularly deserving of this award. The nomination noted Clayton's commitment to teaching and learning, the above-and-beyond work that h…
-

New Ph.D. Graduate
Congratulations to Onur Varol for successfully defending his dissertation entitled "Analyzing Social Big Data to Study Online Discourse and its Manipulation" on April 25th 2017, supervised by Filippo Menczer. Onur completed a PhD degree in the Complex Systems track of the Informatics PhD Program. Onur has accepted a postdoctoral position at Northeastern University at the Center for Complex Networ…
-

New Ph.D. Graduate
Congratulations to Santosh Manicka for successfully defending his dissertation entitled "The Role of Canalization in the Spreading of Perturbations in Boolean Networks" on April 24th 2017, Supervised by Luis Rocha. Santosh completed a PhD degree in the Complex Systems track of the Informatics PhD Program.
-
Talk by Diego Amancio and Filipi Silva
Joint Talk When: Thursday, April 27th, 2017, 2:30 pm Where: Informatics East, Room 322 Speakers: Diego Raphael Amancio and Filipi Nascimento Silva Part One Modelling and characterization of information networks (Diego Raphael Amancio) Complex networks have been used to model a myriad of real systems, including information. In this presentation, I will focus on the application of network science th…
-

New Ph.D. Graduate
Congratulations to Alexander Gates for successfully defending his dissertation entitled "The anatomical and effective structure of complex systems" on April 3rd 2017, co-supervised by Randy beer and Luis Rocha. Alex completed a dual-PhD degree in the Complex Systems track of the Informatics PhD Program as well as the Cognitive Science program at Indiana University. Alex has accepted a postdoctoral…
-
Talk by Hye-Jin Youn
Speaker: Hye-Jin Youn, Santa Fe Institute & Senior Research Fellow, University of Oxford Title: Lost and found in translation: the universal structure of human lexical semantics Date: 04/12/2017 Time: 11am Room: Informatics East 322 Abstract: How universal is human conceptual structure? The way concepts are organised in the human brain may reflect distinct features of cultural, historical, and…
-

Talk by Alessio Cardillo
Speaker: Alessio Cardillo, École Polytechnique Fédérale de Lausanne Title: Automatic identification of relevant concepts in scientific publications Date: 02/10/2017 Time: 12:15pm Room: Informatics East 322 Abstract: Recently, scientists have devoted many efforts to study the organization and evolution of science by exploiting the textual information contained in the articles like: keywords and te…
-

ICWSM 2017 Workshop on Digital Misinformation
Update: workshop report available (AI Magazine Spring 2018 | DOI:10.1609/aimag.v39i1.2783 | Preprint) The deluge of online and offline misinformation is overloading the exchange of ideas upon which democracies depend. Many have argued that echo chambers are increasingly constricting the ability of alternative perspectives to provide a check on one’s viewpoints. Suffering fragmentation and …
-
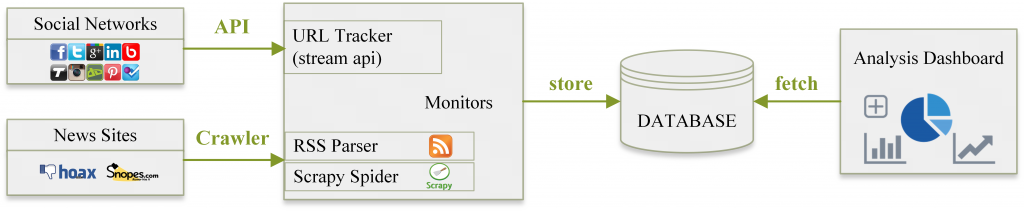
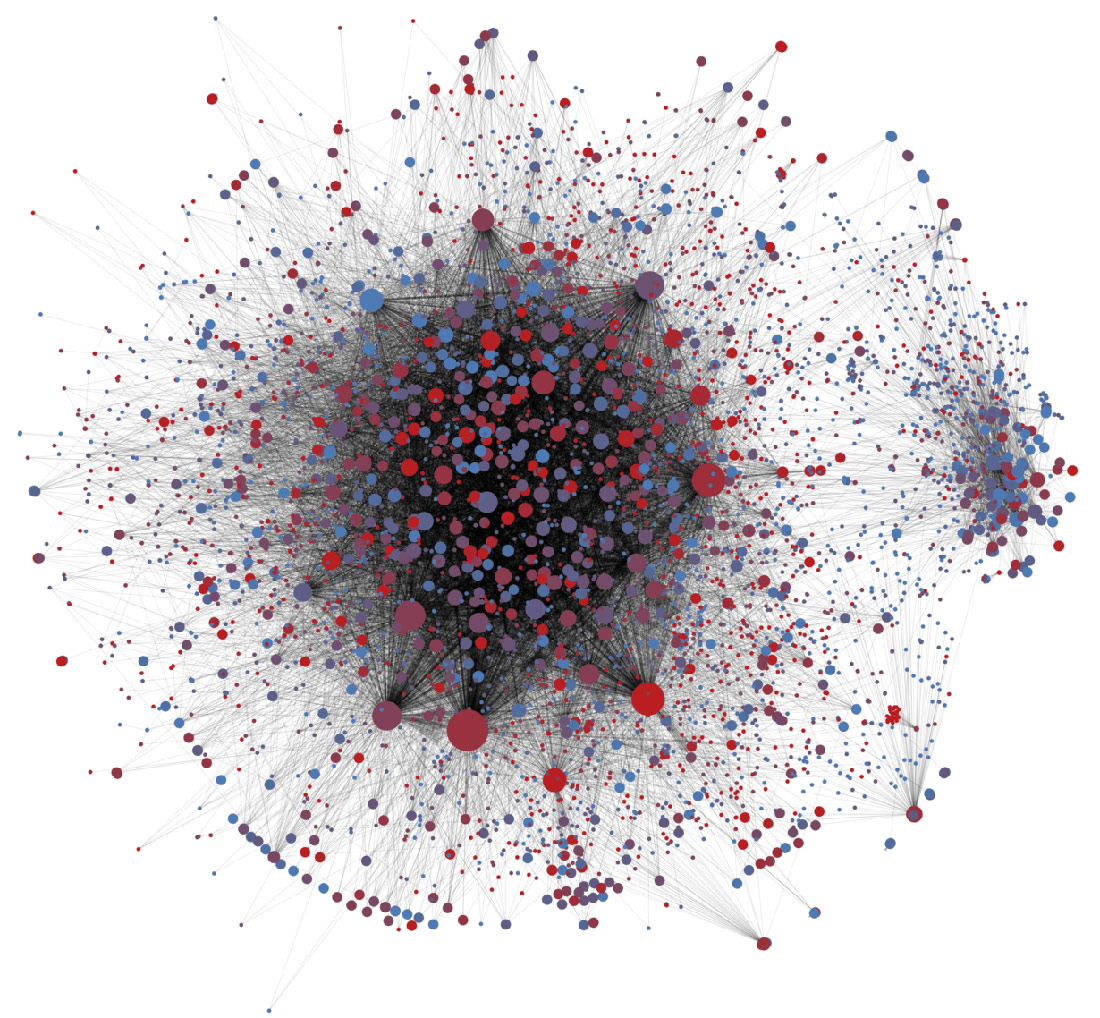
Hoaxy: A Platform for Tracking Online Misinformation
Misinformation (yellow/brown) spreads within the healthy (blue) Twittersphere network. Left: chemtrails conspiracies mix with conversations about the sky. Right: antivax campaigns penetrate discussions about the flu. UPDATE (21 Dec 2016): we just launched Hoaxy, our open platform to visualize the online spread of claims and fact checking. Approximately 65% of American adults access the …
-
Why we study digital misinformation
If you get your news from social media, as most Americans do, you are exposed to a daily dose of hoaxes, rumors, conspiracy theories and misleading news. When it’s all mixed in with reliable information from honest sources, the truth can be very hard to discern. In fact, my research team’s analysis of data from Columbia University’s Emergent rumor tracker suggests that this misinformation is just …
-

Talk by Orion Penner
Speaker: Orion Penner, École polytechnique fédérale de Lausanne Title: The Returns to Scientific Specialization Date: 11/16/2016 Time: 12:30pm Room: Informatics East 322 Abstract: While it is well established that researchers specialize, the extent to which they specialize has gone, largely, unexamined. We have developed an approach for measuring the extent to which a researcher is specialized, a…
-
Cracking the stealth political influence of bots
Among the millions of real people tweeting about the presidential race, there are also a lot accounts operated by fake people, or "bots." Politicians and regular users alike use these accounts to increase their follower bases and push messages. PBS NewsHour science correspondent Miles O’Brien reports on how CNetS computer scientists can analyze Twitter handles to determine whether or not they are …
-
The Spread of Misinformation in Social Media
Watch Fil Menczer's Northwestern Institute on Complex Systems (NICO) seminar about our recent work on the spread of misinformation on social media.
-

Talk by Woo Seong Jo
Speaker: Woo Seong Jo, Sungkyunkwan University Title: Ph.D. Candidate Date: 10/12/2016 Time: 11am Room: Informatics East 322 Abstract: We use user-accessible profiles from a web-based well-known social networking service specialized in business and employment. Users often provide information of their work experiences and positions in firms they worked, and also write what are their work skills. W…
-
The Social Network of Healthcare - How Instagram and Twitter are Providing New Insights
Sponsored by Persistent Systems. Luis Rocha, Director of the Complex Systems PhD track in the School of Information and Computing at Indiana University Bloomington, explains the new software-driven approach to medical research. Big data generated through social media such as Twitter and Instragram provides a far deeper and fuller examination of the impact of medicines and diseases, leading to grea…
-
Art-Science Installation Musical Morphogenesis
‘Musical Morphogenesis’ is an interactive installation that translates to sound, movement and lights the dynamics behind the development of petals in a flower. It is a collaborative piece developed by designers, architects, musicians and scientists in Luis Rocha's CASCI group. The control of this robotic "macroscope" is an implementation of the gene regulatory network of the Thaliana Arabidopsis f…
-

Emilio Ferrara receives Junior Scientific Award at CSS'16
Congratulations to Emilio Ferrara for winning the 2016 Junior Scientific Award from the Complex Systems Society (CCS), which unveiled the winners of the CSS scientific awards in a packed plenary session at ECCS’16 in Amsterdam, the Netherlands. Quoting the nomination: Emilio Ferrara is one of the most active and successful young researchers in the field of computational social sciences. His works…
-
Talk by Lucas Jeub
Speaker: Lucas Jeub, Postdoctoral Fellow, School of Informatics & Computing, Indiana University Title: Local Communities, Mesoscopic Structure, and Multilayer Networks Date: 09/12/2016 Time: 11:30 am Room: Informatics East 322 Abstract: There are many methods to detect dense “communities” of nodes in networks, and there are now several methods to detect communities in multilayer networks. One…
-

Social bot research featured on CACM, IEEE Computer covers
Research on detection of social bots by CNetS faculty members Alessandro Flammini and Filippo Menczer, former IUNI research scientist Emilio Ferrara, and graduate students Clayton Davis, Onur Varol, and Prashant Shiralkar was featured on the covers of the two top computing venues: the June issue of Computer (flagship magazine of the IEEE Computer Society) and the July issue of Communications …
-

Quirkies Evolution
Lately, my hobby has been to develop Quirkies Evolution, an iOS game to teach kids about evolution. This started last year as the 4th-grade science project of my daughter, Iris. She asked for advice about a project idea; she wanted it to be about coding and evolution, two subjects about which she has been learning recently. So we ended up designing Quirkies together, and she used the app to run so…
-

CASCI alumnus makes Fast Company's most creative list
Ahmed Abdeen Hamed Congratulations to CASCI alumnus Dr. Ahmed Abdeen Hamed who was recognized by FastCompany magazine, among the most creative people in the world, in 2016, for his research publication entitled: Twitter K-H networks in action: Advancing biomedical literature for drug search.Dr. Hamed completed his Computer Science MS degree at Indiana University in May 2005 and joined o…
-
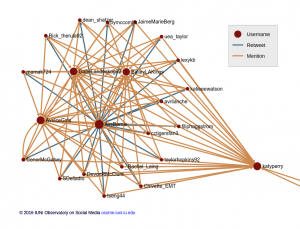
OSoMe tools to analyze online trends, memes
Did more people see #thedress as blue and black or white and gold? How many Twitter users wanted pop star Katy Perry to take the #icebucketchallenge? The power to explore online social media movements — from the pop cultural to the political — with the same algorithmic sophistication as top experts in the field is now available to journalists, researchers and members of the public from a free, use…
-

NaN represented, recognized at SoIC Spring Research Symposium
On Tuesday, April 19, IU School of Informatics and Computing hosted its Spring Research Symposium, where NaN was represented by two undergraduate research projects mentored by PhD candidate Clayton A Davis. Keychul Chung received 2nd prize honors for his work on a browser-based tool to compare historical trends of Twitter hashtag use. Kibeom Alex Hong presented a web-based tool to visualize geospa…
-

Talk by Ricardo Baeza-Yates: Data and Algorithmic Bias in the Web
Speaker: Ricardo Baeza-Yates, Universitat Pompeu Fabra, Spain & Universidad de Chile Title: Data and Algorithmic Bias in the Web Date: 04/22/2016 Time: 9am Room: Info East 122 Abstract: The Web is the largest public big data repository that humankind has created. In this overwhelming data ocean we need to be aware of the quality and in particular, of biases that exist in this data, such as re…
-
Control of Complex Networks
Control of the eukaryotic cell cycle of budding yeast Saccharomyces cerevisiae (from Nature.com, click for details) Network science has allowed us to understand the organization of complex systems across disciplines. However, there is a need to understand how to control them; for example, to identify strategies to revert a diseased cell to a healthy state in cancer treatme…
-

Best presenter prize at WWW Developers Day
Congratulations to Clayton Davis, who won the best presenter prize at WWW 2016 Developers Day! Clayton presented BotOrNot: A system to evaluate social bots, a paper coauthored with Onur Varol, Emilio Ferrara, Alessandro Flammini and Filippo Menczer, that describes our latest API developments with the BotOrNot system.
-
Three postdoc positions in complex networks and systems
The Center for Complex Networks and Systems Research (CNetS.indiana.edu), jointly with the Indiana University Network Science Institute (IUNI.iu.edu), has two three open postdoctoral positions, two on the characterization and modeling of complex systems and one to study critical processes in networks of networks. The appointments start in Summer/Fall 2016 for one year and are renewable for one or …
-

What makes something go viral online?
In an interview aired on the ABC (Australian) evening news program "The World" on April 4, 2016, Filippo Menczer discussed with host Beverley O'Connor how information and misinformation spread throughout the Internet and the roles of network structure and social bubbles in determining meme virality. Video here.
-

Artemy Kolchinsky, recent Postdoc at the Santa Fe Institute
Artemy Kolchinsky Recent CASCI Complex Systems & Networks Phd program graduate Artemy Kolchinsky, is now a postdoc at the Santa Fe Institute. While at SFI, Kolchinsky is working with "David Wolpert on several projects related to optimal use of information and prediction. One is the problem of modeling and analyzing complicated dynamical systems that require large amounts of time and…
-

Rocha Receives Fulbright Scholarship
Luis M. Rocha Congratulations to Luis Rocha, who has been awarded a Fulbright Scholarship devoted to developing Complex Systems methodologies for the Life Sciences. The 12-month sabbatical is to be pursued under the Fulbright program for educational exchanges between the United States and Portugal. It will focus on studying collective behavior and control in biochemical and social networks.…
-

Talk by Pan-Jun Kim
Speaker: Pan-Jun Kim, Leader of the Junior Research Group at the Asia Pacific Center for Theoretical Physics Title: I Am My Genes, Wire, and Microbes Date: 03/09/2016 Time: 1:00pm Room: Informatics East 122 Abstract: A primary challenge in biology is to explain how complex phenotypes arise from individual molecules encoded in genes. Molecular interaction networks offer a key to understand how gen…
-
Talk by Michal B. Paradowski
Speaker: Michal B. Paradowski, Assistant Professor Institute of Applied Linguistics, University of Warsaw Title: Complexity phenomena in linguistics Date: 03/11/2016 Time: 3:30pm Room: Informatics East 122 Abstract: Throughout history language sciences have been dealing with numerous phenomena that are either inherently complex/dynamic systems, or which display characteristic properties of such sy…
-
Talk by Alberto Pepe
Speaker: Alberto Pepe, Authorea Title: Data-driven, Interactive Scientific Articles in a Collaborative Environment with Authorea Date: 02/19/2016 Time: 3:30pm Room: Informatics East 130 Abstract: Most tools that scientists use for the preparation of scholarl…
-

Talk by Rossano Schifanella
Speaker: Rossano Schifanella, University of Turin Title: Mapping the Sensorial Layers of a City Date: 01/29/2016 Time: 4pm Room: Informatics East 130 Abstract: Researchers have used large quantities of online data to study dynamics in novel ways. Consider the specific case of online networked individuals (e.g., users of Twitter, Instagram, Flickr). Can their social dynamics be used to build bette…
-

Radicchi Earns NSF CAREER Award
Filippo Radicchi Congratulations to Filippo Radicchi, who has been awarded a Faculty Early Career Development (CAREER) grant from the National Science Foundation to establish a research and education program devoted to studying critical infrastructures from the perspective of network theory. The $500,000 grant will focus on how physical networks, such as transportation, water, food supp…
-
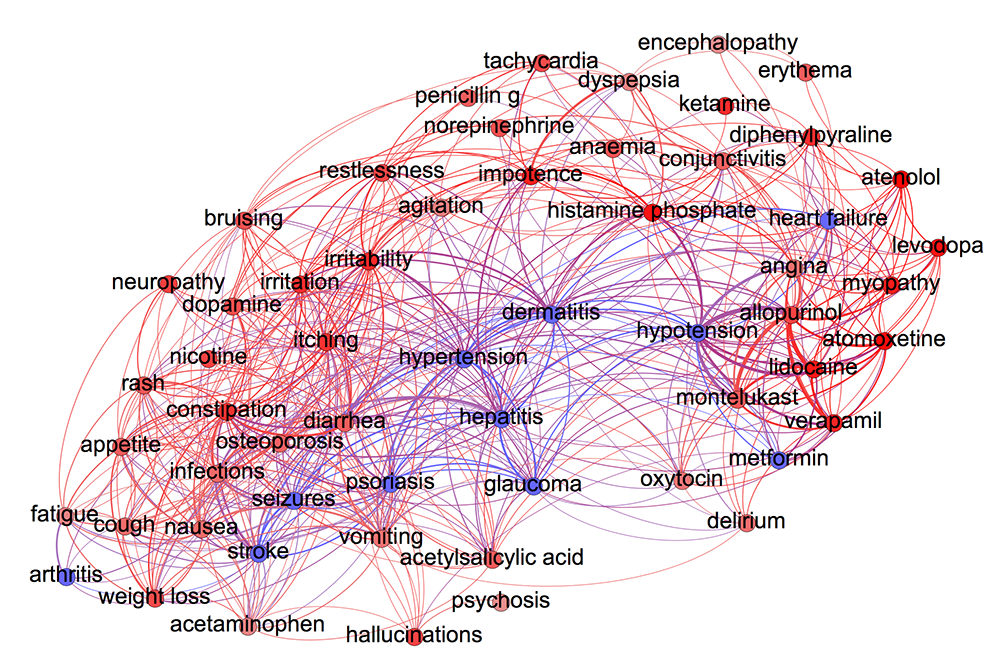
CNETS Team Uses Instagram to monitor Drug Interactions and Adverse Reactions
Subnetwork of symptoms and drugs associated with Psoriasis and Epilepsy Update: On March 21st, 2016 the paper described below (PMC4720984) was highlighted by Russ Altman from Stanford University in his yearly review as one of 30 important papers of the year in translational bioinformatics. Using complex networks analysis and social media mining, CNETS researchers from the CASCI team hav…
-
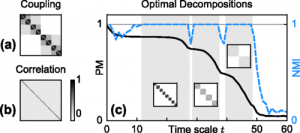
CNetS team studies generalized modularity in complex networks & Systems
Modularity in complex systems can be observed in networks and across dynamical states, time scales, and in response to different kinds of perturbations. In a paper published in Physical Review E (Rapid Communication), Kolchinsky, Gates & Rocha propose a principled alternative to detecting communities in static and dynamical networks. The method demonstrates that standard modularity measures on…
-
Awards at CCS 2015
The CNetS poster "The Rise of Social Bots in Online Social Networks" by Emilio Ferrara, Onur Varol, Prashant Shiralkar, Clayton Davis, Filippo Menczer, and Alessandro Flammini won a Best Poster Award at CCS 2015. The poster was presented by Clayton Davis. The results will also appear in the paper "The Rise of Social Bots" to be published in Comm. ACM (in press, preprint). The paper "Modularity and…
-
Talk by Mike Conover
Speaker: Mike Conover, LinkedIn Title: Unleashing the Hidden Power of Gephi Date: 10/06/2015 Time: 5:15 pm Room: Informatics West 232 Abstract: Gephi is a familiar standard for exploring the structure of complex networks. Powerful though it is, much of its core functionality remains hidden behind non-obvious user interface elements. In this tutorial session, I'll review some advanced techniques fo…
-

CNetS researchers use Instagram to predict success of fashion models
Predicting popularity and success in cultural markets is hard due to strong inequalities and inherent unpredictability. A good example comes from the world of fashion, where industry professionals face every season the difficult challenge of guessing who will be the next seasons' top models. A recent study by CNetS graduate student Jaehyuk Park, research scientist Giovanni Luca Ciampaglia (also at…
-
Talk by Minsu Park
Speaker: Minsu Park, Cornell University Title: Understanding Musical Diversity via Online Media Date: 08/07/15 Time: 2:00 pm Room: Informatics East 122 Abstract: Musicologists and sociologists have long been interested in patterns of music consumption and their relation to socioeconomic status. In particular, the Omnivore Thesis examines the relationship between these variables and the diversity o…
-

On the cover of Neuron
Work by Olaf Sporns, YY Ahn, Alessandro Flammini and colleagues was featured on the cover of Neuron. In the paper Cooperative and Competitive Spreading Dynamics on the Human Connectome, the authors present a simulation model of spreading dynamics, previously applied in studies of social networks, that offers a new perspective on how the connectivity of the human brain constrains neural communicati…
-
Talk by Mike Conover
Speaker: Mike Conover (LinkedIn) Title: Building Machine Learning Systems at LinkedIn Date: 06/30/2015 Time: 4pm Room: Informatics East 122 Abstract: This talk details patterns and machine learning systems to provide our members with actionable, relevant opportunities to nurture their professional networks. Featuring the Connected mobile app as an in-depth case study of how to combine compute-inte…
-
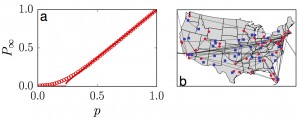
CNetS researcher studies percolation in real interdependent networks
Our understanding of how catastrophe propagates in multi-layered networks relies on theories that apply only to infinite systems. As a paper published in Nature Physics by Filippo Radicchi demonstrates, reducing an interconnected network of finite size to a multiset of decoupled graphs provides a route to understanding catastrophic events in real systems.
-

CNetS research at CCS'15
Big success for CNetS researchers at the Conference on Complex Systems (CCS'15)! Here are the accepted talks from our center: Computational fact checking from knowledge networks by Giovanni Luca Ciampaglia, Prashant Shiralkar, Johan Bollen, Luis M Rocha, Filippo Menczer and Alessandro Flammini Control of complex networks requires structure and dynamics by Alexander Gates and Luis M. Rocha Darwin…
-
CNetS researchers study sleeping beauties
Why do some research papers remain dormant for years and then suddenly explode with great impact upon the scientific community? These “sleeping beauties” are the subject of a new study by CNetS researchers Qing Ke, Emilio Ferrara, Filippo Radicchi, and Alessandro Flammini published in the Proceedings of the National Academy of Sciences. The study provides empirical evidence that a paper can truly …
-

CNetS team winner in LinkedIn Economic Graph Challenge
The CNetS team LinkedIn announced that YY Ahn and his team of Ph.D. students from the Center for Complex Networks and Systems Research, including Yizhi Jing, Adazeh Nematzadeh, Jaehyuk Park, and Ian Wood, is one of the 11 winners of the LinkedIn Economic Graph Challenge. Their project, “Forecasting large-scale industrial evolution,” aims to understand the macro-evolution of industries t…
-

New PhD graduate
Congratulations to Artemy Kolchinsky a brand new PhD in 2015 in the Complex Systems track of the Informatics PhD Program. Artemy's PhD Dissertation is entittled "Measuring Scales: Integration and Modularity in Complex Systems". Artemy Kolchinsky Dissertation Defense. April 2015.
-
New CASCI papers on Complex Networks
Read new papers from CASCI on developing the mathematical toolbox available to deal with computing distances on weighted graphs, applying distance closures for computational fact checking, and computing multi-scale integration in brain networks: T. Simas and L.M. Rocha [2015]."Distance Closures on Complex Networks". Network Science, doi:10.1017/nws.2015.11. G.L. Ciampaglia, P. Shiralkar, L.M. Roch…
-

Indiana University Network Science Institute
IUNI announcement in Science magazine The new Indiana University Network Science Institute (IUNI) unites 100+ researchers at IU — building on their world-renowned multidisciplinary expertise toward further scientific understanding of the complex networked systems of our world. Through pioneering new approaches in mapping, representing, visualizing, modeling, and analyzing …
-
We're hiring!
The School of Informatics and Computing (SoIC) at Indiana University Bloomington invites applications by Dec 1, 2014 for an asst/assoc/full professor position in complex networks and systems, in the Informatics Division, to begin in August 2015. The position is expected to be filled at the senior level, but outstanding junior candidates will be considered. Applications are especially enco…
-
NIH Project to study Drug-Drug Interaction
Prof. Luis Rocha from CNETS at IU Bloomington, Prof. Lang Li from IUPUI Medical School, and Prof. Hagit Shatkay from the University of Delaware have been awarded a four-year, $1.7M grant from NIH/NLM to study the large-scale extraction of drug-Interaction from medical text. Drug-drug interaction (DDI) leads to adverse drug reactions, emergency room visits and hospitalization, thus posing a major …
-

Radicchi wins first CSS junior scientific award
Filippo Radicchi at ECCS 2014 Congratulations to Filippo Radicchi for winning the First Junior Scientific Award from the Complex Systems Society (CCS), which unveiled the winners of the first CSS scientific awards in a packed plenary session at ECCS’14 in Lucca, Italy. CSS also honored Prof. Eugene Stanley with the Senior Scientific Award, and Dr. Giovanna Miritello with a second Junior Sci…
-
Persistent Systems Project
A new grant to analyze social media for health risks and adverse drug reactions from Persistent Systems, was awarded to Luis Rocha and CASCI.
-

The Truth about Truthy
The Truthy project was misrepresented in 'The Kelly File' and several other Fox News broadcasts. Public domain photo by MattGagnon via Wikimedia Commons. For the past four years, researchers at the Center for Complex Networks and Systems Research at the Indiana University School of Informatics and Computing have been studying the ways in which information spreads on social media network…
-
Best paper award at WebSci14
Congratulations to Onur Varol, Emilio Ferrara, Chris Ogan, Fil Menczer, and Sandro Flammini for winning the ACM Web Science 2014 Best Paper Award with their paper Evolution of online user behavior during a social upheaval (preprint). In the paper, the authors study the pivotal role played by Twitter during the political mobilization of the Gezi Park movement in Turkey. By analyzing over 2.3 millio…
-
Advice on grad school and the PhD
If you are contemplating grad school in general or applying for one of our PhD programs, and in particular if you are thinking about doing research with me, please take a look at these resources before you contact me: Should You Go To Grad School? Recipes for PhD 10 easy ways to fail a Ph.D. Advice for students and junior researchers Ten things I wish I knew before starting on a PhD Grad School A…
-

YY Ahn named Microsoft Research Faculty Fellow for 2014
YY Ahn is one of the 2014 MSR Faculty Fellows Each year since 2005, Microsoft Research has awarded Microsoft Research Faculty Fellowships to promising, early-career academics who are engaged in innovative computing research and have the potential to make significant advances in the state of the art. These fellowships—which include a cash award and access to software, invit…
-

WebSci14
We are excited to announce that the ACM Web Science 2014 Conference will be hosted by our center on the beautiful IUB campus June 23–26, 2014. Web Science studies the vast information network of people, communities, organizations, applications, and policies that shape and are shaped by the Web, the largest artifact constructed by humans in history. Computing, physical, and social sciences come to…
-
Talk by Giovanni Petri
Speaker: Giovanni Petri, Institute for Scientific Interchange (ISI) Title: Computational Topology for Complex Networks Date: 05/15/2014 Time: 1pm Room: Informatics West 107 Abstract: Topological methods for data analysis have recently attracted large attention due to their capacity to capture mesoscopic features which are lost under standard network technique. In the first part of this talk I will…
-
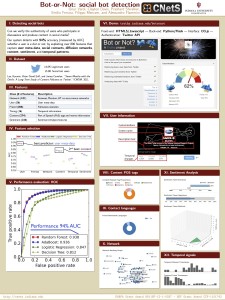
DESPIC team presents Bot Or Not demo and six posters at DoD meeting
The DESPIC team at the Center for Complex Systems and Networks Research (CNetS) presented a demo of a new tool named BotOrNot at a DoD meeting held in Arlington, Virginia on April 23-25, 2014. BotOrNot (truthy.indiana.edu/botornot) is a tool to automatically detect whether a given Twitter user is a social bot or a human. Trained on Twitter bots collected by our lab and the infolab at Texas A&…
-

Congratulations to Dr. Lilian Weng!
Lilian Weng with her PhD committee Congratulations to Lilian Weng, who successfully defended her Informatics PhD dissertation titled Information diffusion on online social networks. The thesis provides insights into information diffusion on online social networks from three aspects: people who share information, features of transmissible content, and the mutual effects bet…
-

New York Times and The Good Wife on Socialbots
A scene from an episode of The Good Wife inspired by our work on socialbots On August 11, 2013, the New York Times published an article by Ian Urbina with the headline: I Flirt and Tweet. Follow Me at #Socialbot. The article reports on how socialbots (software simulating people on social media) are being designed to sway elections, to influence the stock market, even to f…
-
ACM and Kinsey honors
ACM, the professional association of computer scientists and computing professionals, announced today that I was named a Distinguished Scientist. Here is the list of other ACM members who got this award. This is a great honor and I am grateful. But my thanks go especially to my many amazing collaborators (colleagues, postdocs, visiting scholars, and especially students) without whom my contributio…
-
Talk by Jisun An
Speaker: Jisun An, PhD candidate, University of Cambridge Title: Analyzing Social Media for Designing Fit-For-Purpose Systems: From Politics to Business Date: 11/19/2013 Time: 11am Room: Informatics East 122 Abstract: Researchers in different disciplines have been studying human behavior in a variety of contexts, and have largely done so upon small-scale data coming from surveys and ethnographic o…
-
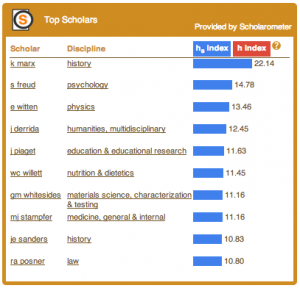
Nature story on universality of impact metrics
You can embed this top scholars widget from Scholarometer A story in Nature discusses a recent paper (preprint) from CNetS members Jasleen Kaur, Filippo Radicchi and Fil Menczer on the universality of scholarly impact metrics. In the paper, we present a method to quantify the disciplinary bias of any scholarly impact metric. We use the method to evaluate a number of establ…
-
National Coverage for "More Tweets, More Votes"
Findings by CNetS researchers on social media indicators of election results received significant coverage in the national press. The paper More Tweets, More Votes: Social Media as a Quantitative Indicator of Political Behavior by Joseph Digrazia, Karissa McKelvey, Johan Bollen, and Fabio Rojas was presented at the 2013 Meeting of the American Sociological Association in NYC. It was covered by NPR…
-

Truthy Team Wins WICI Data Challenge
Congratulations to Przemyslaw Grabowicz, Luca Aiello, and Fil Menczer for winning the WICI Data Challenge. A prize of $10,000 CAD accompanies this award from the Waterloo Institute for Complexity and Innovation at the University of Waterloo. The Challenge called for tools and methods that improve the exploration, analysis, and visualization of complex-systems data. The winning entry, titled Fast v…
-

ISI Fellows 2013
Alex Vespignani inducts Fil Menczer as ISI Fellow On June 27, 2013, in Turin, within the celebrations of the Lagrange Prize and ISI Foundation’s 30th anniversary, Fil Menczer and nine other scientists were named ISI Fellows. The recognition is a tribute to researchers whose scientific contribution is of primary importance for the Institute. The official investiture took p…
-
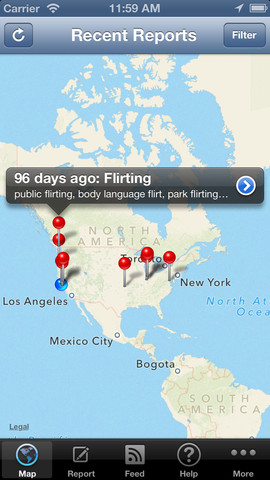
Kinsey Reporter launch
Kinsey Reporter App UPDATE: With legal review completed, we re-launched Kinsey Reporter V.2! CNetS, in collaboration with The Kinsey Institute, has released Kinsey Reporter, a global mobile survey platform for collecting and sharing anonymous data about sexual and other intimate behaviors. The pilot project allows citizen observers around the world to use free applications…
-

David Crandall's Career Award
David Crandall Congratulations to David Crandall for his NSF CAREER Award! The Faculty Early Career Development (CAREER) Program is a Foundation-wide activity that offers the National Science Foundation's most prestigious awards in support of junior faculty who exemplify the role of teacher-scholars through outstanding research, excellent education and the integration of e…
-

New Indiana University Collaborative Research Grant 2013
The project "Social SLAM: Creating Dynamical Socio-Environmental Models for Mobile Robots", a collaboration between Luis Rocha, Selma Sabanovic, Matt Francisco, and Alin Cosmanescu, has received an IUCRG grant for 2013-2014 from the Office of the Vice President for Research at Indiana University.
-
Highly accessed paper in BMC Bioinformatics
The pharmacokinetics ontology and corpus for text mining developed in collaboration with Li's lab at IUPUI, part of CASCI Biomedical Literature Mining work, has been reported in BMC Bioinformatics where it has become a Highly Accessed paper: Wu, Hengyi, S. Karnik, A. Subhadarshini, Z. Wang, S. Philips, X. Han, C. Chiang, L. Liu, M. Boustani, L.M. Rocha, S.K. Quinney, D.A. Flockhart and L. Li [2013…
-
Canalization and Control in Automata Networks
Dynamical Modularity Read our latest paper titled Canalization and Control in Automata Networks: Body Segmentation in Drosophila melanogaster in PLoS ONE. Authors Manuel Marques-Pita & Luis Rocha ask, How do cells and tissues 'compute'? Schema redescription is presented as a methodology to characterize canalization in automata networks used to model biochemical regulation and signal…
-
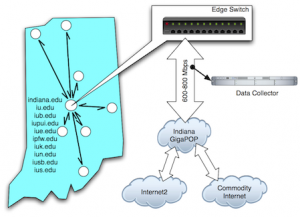
Dataset of 53.5 billion clicks available
IU Click Collection System To foster the study of the structure and dynamics of Web traffic networks, we are making available to the research community a large Click Dataset of 13 53.5 billion HTTP requests collected at Indiana University. Between 2006 and 2010, our system generated data at a rate of about 60 million requests per day, or about 30 GB/day of raw data. We hop…
-
Social Dynamics of Science
Read our latest paper titled Social Dynamics of Science in Nature Scientific Reports. Authors Xiaoling Sun, Jasleen Kaur, Staša Milojević, Alessandro Flammini & Filippo Menczer ask, How do scientific disciplines emerge? No quantitative model to date allows us to validate competing theories on the different roles of endogenous processes, such as social collaborations, and exogenous events, such…
-

Postdoctoral Researcher in Analysis and Modeling of Social Networks
[UPDATE: this position has been filled.] The Center for Complex Networks and Systems Research has an open postdoctoral position to study how ideas propagate through complex online social networks. The position is funded by a McDonnell Foundation's grant in Complex Systems. The appointment starts as early as possible after January 2013 for one year and is renewable for up to 2 additional years. Th…
-

PLEAD 2012 keynote
I was honored to give a keynote presentation at PLEAD 2012, the CIKM Workshop on Politics, Elections and Data. My talk was titled The diffusion of political memes in social media. The workshop was held in beautiful Maui Hawaii, but alas, I could not attend in person and gave the presentation remotely via skype :-(
-
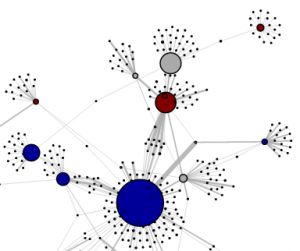
Truthy elections analytics tool
Research by our Truthy team was recently featured in New Scientist, USA Today, and the cover story of Science News. The Truthy project, developed by CNetS researchers and doctoral students, aims to study the factors affecting the spread of information — and misinformation — in social media. The Truthy site charts tweet sentiment and volume related to themes such as social movements and news. It …
-
Talk by Zhong-Yuan Zhang
Speaker: Zhong-Yuan Zhang Title: Semi-Supervised Community Structure Detection in Social Networks Based on Matrix De-noising Date: 10/15/2012 Time: 1pm Room: Informatics East 122 Abstract: Constrained clustering has been well-studied in the unsupervised learning society. However, how to encode constraints into community detection process of the complex social networks remains a challenging problem…
-
Talk by Cosma Shalizi
Speaker: Cosma Shalizi, Carnegie Mellon University Title: Homophily, Contagion, Confounding: Pick Any Three Date: 11/27/2012 Time: 1pm Room: Informatics East 130 Abstract: A person's behavior can often be predicted from that of their neighbors in a social network. This is sometimes explained by homophily, the tendency to form social ties with others because we resemble them. It is also sometimes …
-

Web Science Lab and Web Science Network
We welcome the Web Science Lab to our center! This underscores our ongoing collaborations in the emerging discipline of Web Science. Since February 2012, CNetS is a member of WSTNet, an international network bringing together world-class research laboratories to support the Web Science research and education program. The Web Science Network of Laboratories combines some of the world’s leading aca…
-
IARPA contract to study new ways to forecast critical societal events
University and industry scientists are determining how to forecast significant societal events, ranging from violent protests to nationwide credit-rate crashes, by analyzing the billions of pieces of information in the ocean of public communications, such as tweets, web queries, oil prices, and daily stock market activity. "We are automating the generation of alerts, so that intelligence analysts …
-

New Journals: Network Science and EPJ Data Science
Network Science is a new journal for a new discipline -- one using the network paradigm, focusing on actors and relational linkages, to inform research, methodology, and applications from many fields across the natural, social, engineering and informational sciences. Given growing understanding of the interconnectedness and globalization of the world, network methods are an increasingly recognized…
-

Welcome to two new postdocs
Ruby Emilio We welcome two postdoctoral associates who just joined our center. Ruby Wang got her PhD in Physics from Central China Normal University in 2009. Emilio Ferrara got his PhD in Mathematics (Computer Science) from the University of Messina in Italy in 2012. Both will work on projects related to the diffusion of information in social media…
-

Karissa McKelvey gets Provost's Award for Undergraduate Research and Creative Activity
Congratulations to Karissa McKelvey for being one of six undergraduate students at Indiana University Bloomington who have received the 2011-12 Provost's Award for Undergraduate Research and Creative Activity. A senior in the School of Informatics and Computing from Santa Rosa, Calif., Karissa is working with Filippo Menczer on the Truthy project, which analyzes and makes accessible a massive stre…
-

Competition among memes in a world with limited attention
Lilian In our paper on Competition among memes in a world with limited attention in Nature Scientific Reports, Lilian Weng and coauthors Sandro Flammini, Alex Vespignani, and Fil Menczer report that we can explain the massive heterogeneity in the popularity and persistence of memes as deriving from a combination of the competition for our limited attention and the structure of the socia…
-
Talk by Robert J. Glushko
Speaker: Robert J. Glushko, School of Information, University of California-Berkeley Title: The Discipline of Organizing Date: 04/09/2012 Time: 4pm Room: Psychology 101 Abstract: We organize things, we organize information, we organize information about things, and we organize information about information. But even though “organizing” is a fundamental and ubiquitous challenge, when we compare the…
-
Talk by Qiaozhu Mei
Speaker: Qiaozhu Mei, School of Information, University of Michigan Title: The Foreseer: Integrative Retrieval and Mining of information in Online Communities Date: 03/02/2012 Time: 12:00pm Room: Informatics West 105 Abstract: With the growth of online communities, the Web has evolved from networks of shared documents to networks of knowledge-sharing groups and individuals. A vast amount of hetero…
-

Welcome and congratulations to YY Ahn!
We are excited to welcome a new faculty member, Yong-Yeol "YY" Ahn, to our center. Prior to joining IU, YY was a postdoctoral researcher at the Center for Complex Network Research at Northeastern University and a visiting researcher at the Center for Cancer Systems Biology at Dana-Farber Cancer Institute, working with Albert-László Barabási. YY has a PhD in Physics from KAIST in Korea. His work ex…
-

DARPA award
Prof. Flammini (PI) and Menczer have been awarded a three-year, $2M grant from DARPA in the context of the Social Media in Strategic Communication (SMISC) program, whose primary goal is “to develop a new science of social networks built on an emerging technology base,” Our IU unit leads a three-group team that includes collaborators at Lockheed-Martin Advanced Technology Lab and the University of …
-

Google gift supports Espresso Club
Google committed to a yearly gift of $700 to CNetS to support our Espresso Club. This will allow us to heavily subsidize the cost of coffee for our grad students, furthering the club's mission to transform caffeine into science. Our thanks to Google!
-

AAAS 2012
I will give an embargoed talk on Tracking the Diffusion of Ideas in Social Media at the AAAS Annual Meeting on 18 Feb 2012, as part of the Symposium on Web Surveillance. The AAAS Annual Meeting (Feb 16-20 in Vancouver) is the premier multi-disciplinary gathering of the world's leading scientists. The theme of this year's Annual Meeting is Flattening the World: Building a Global Knowledge Society. …
-
Talk by Daniel Romero
Speaker: Daniel Romero, Center for Applied Mathematics, Cornell University Title: The Mechanics of Network Formation and Information Diffusion on Social Media Sites Date: 12/02/11 Time: 10:30 a.m. Room: Informatics West 105 Abstract: Today’s online social networks and social media sites contain a combination of social and informational ties that serve as bridges for different types of information …
-
Talk by Pan-Jun Kim
Speaker: Pan-Jun Kim, University of Illinois Title: Sociology in the genetic world: What we can learn from microbial genetic co-occurrence Date: 11/21/2011 Time: 11am Room: Informatics East 122 Abstract: The phenotype of any organism on earth is, in large part, the consequence of interplay between numerous gene products encoded in the genome, and such interplay between gene products may affect the…
-

New Journal: EPJ Data Science
The 21st century is currently witnessing the establishment of data-driven science as a complementary approach to the traditional hypothesis-driven method. This (r)evolution accompanying the paradigm shift from reductionism to complex systems sciences has already largely transformed the natural sciences and is about to bring the same changes to the techno-socio-economic sciences, viewed broadly. EP…
-

2011 Truthy Updates
Mike Conover in the WSJ's report on the Truthy project We're pleased to report several exciting developments in our interdisciplinary project studying information diffusion in complex online social networks. The past year has resulted in several publications. Our results on the Truthy astroturf monitoring and detection system were presented at WWW 2011 and ICWSM 2011. Research into the …
-

Postdoctoral Researcher in Analysis and Modeling of Social Networks
The Center for Complex Networks and Systems Research has an open postdoctoral position to study how ideas propagate through complex online social networks. The position is funded by a McDonnell Foundation's grant in Complex Systems. The appointment starts in January 2012 for one year and is renewable for up to 3 additional years. The salary is competitive and benefits are generous. The postdoc wi…
-
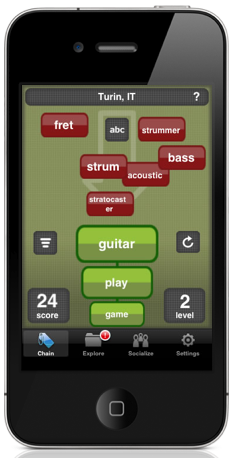
Great Minds Think Alike
Check out the Great Minds Think Alike game for iPhone, iPad and iPod Touch. It is a word association game that lets users build semantic concept networks and explore similarity relations between people and media content. Starting from a single word, the player builds a chain of words by selecting semantically related terms. Get the game from the App Store!
-

Congratulations Jacob!
Dr. Jacob Congratulations to Dr. Jacob Ratkiewicz! Jacob successfully defended his dissertation titled The Expression of Human Behavior in Online Networks on May 2, 2011 and will take a position at Google in July. We will miss him!
-

Paper on Web traffic modeling presented at WAW 2010
Dr. Mark Meiss On December 16, Mark Meiss presented our paper "Modeling Traffic on the Web Graph" (with Bruno, José, Sandro, and Fil) at the 7th Workshop on Algorithms and Models for the Web Graph (WAW 2010), at Stanford. In this paper we introduce an agent-based model that explains many statistical features of aggregate and individual Web traffic data through realistic elements such a…
-
CNetS research associates present epidemic visualization and modeling tools at New Orleans supercomputing conference
Duygu Balcan and Bruno Gonçalves represented the Pervasive Technology Institute and the Center for Complex Networks and Systems at the 23rd Supercomputing Conference in New Orleans. At the conference they presented the Global Epidemic and Mobility (GLEaM) computational tool and the novel visualization component “Epidemic Planet” to researchers from the public and private sectors around the world.…
-

LaNeT-vi visualization featured on the cover of Nature Physics
Cover of Nature Physics Nov. Edition LaNeT-vi, a program that represents large-scale networks in two-dimensions, was used to create the cover image for the November edition of Nature Physics. The featured image highlights several nodes in the foreground that stand out from the rest of the network, highlighting the main thrust of the journal's cover story; the most efficien…
-
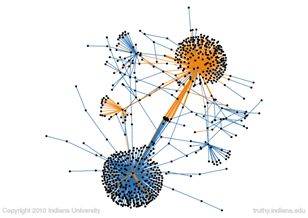
Truthy tool identifies smear tactics on Twitter
Astroturfers, Twitter-bombers and smear campaigners need beware this election season as a group of leading Indiana University information and computer scientists today unleashed Truthy.indiana.edu, a sophisticated new Twitter-based research tool that combines data mining, social network analysis and crowdsourcing to uncover deceptive tactics and misinformation leading up to the Nov. 2 elections. C…
-

"Clouds are not spheres, mountains are not cones.”
Initial image of a zoom sequence: Mandelbrot set with continuously colored environment (Created by Wolfgang Beyer with the program Ultra Fractal 3) Benoit B. Mandelbrot, the ‘Father of Fractals’, died Thursday, October 14 in Cambridge, Mass. He was 85. His passing marks a great loss for science. Fractal mathematics has provided us with the key to accessing the geometric complexity of na…
-
CNetS Associate Professor Johan Bollen interviewed on CNBC and CNN for his work on sentiment tracking via Twitter
Johan Bollen discussed his findings that the public’s collective mood as expressed on Twitter correlates in a surprising way to the performance of the Dow Jones Industrial Average today on CNBC’s Squawk on the Street and CNN International’s Quest Means Business. Bollen explained that contrary to expectations, the public’s overall anxiety appears to predict DJIA closing values three to four days i…
-
New article published in Physical Review Letters puts forth new model of online popularity dynamics
Online popularity can be thought of as analogous to an earthquake; it is sudden, unpredictable, and the effects are severe. While shifts in online popularity are not inherently destructive – consider the unprecedented magnitude of online giving via Twitter following the disaster in Haiti – they indicate radical swings in society’s collective attention. Given the increasingly profound effect that l…
-

Future Internet and Society
In October I was invited to speak at the High-Level Research Conference on Future Internet and Society: A Complex Systems Perspective, organized by ESF (European Science Foundation) and COST (European Cooperation in Science and Technology). Apart from the very interesting topic, and several great talks, I got to chat and play with some fantastic friends and colleagues in a gorgeous place, Maratea …
-

Summer 2010 conferences
NaN folks were busy during the summer. First, we descended to Riva del Garda for Sunbelt XXX, the social networks conference. Rossano presented a poster on social link prediction from shared metadata (with Alain, Ciro, Ben, Fil); Fil presented a paper on Scholarometer (with Diep); and Sandro presented a paper on Wikipedia traffic modeling (with Jacob and Fil). Then Lilian went to Wshington, DC whe…
-

Article in Nature on the plenitude of scientific performance metrics features the research of Bollen and Vespignani
The relatively new field of bibliometrics has experienced an explosion of research as scientists become more interested in developing metrics that can accurately measure scientists’ performance. The common but naive practice of tallying the number of journal citations accumulated by researchers has serious limitations insofar as many salient factors like the weight of a citation as a function of a…
-

Yahoo! Faculty Research and Engagement award
Fil received a $10k Yahoo! Faculty Research and Engagement award to study methodologies to infer user intents and goals based on social similarity measures. This project is in collaboration with Debora Donato of Yahoo! Labs, and Luca Aiello and Giancarlo Ruffo of the University of Torino, Italy.
-

Congratulations Mark, Diep, and Namrata!
Dr. Mark Meiss Diep Hoang Namrata Lele Congratulations to Mark Meiss for successfully defending his doctoral dissertation on Structural mining of large-scale behavioral data from the Internet, and earning his PhD. Mark's dissertation and defense were exemplary and we're lucky to keep him in CNetS for a bit longer as a postdoc before he joins Google. Also graduating…
-
Scholarometer presented at WebSci2010
Scholarometer is becoming a more mature tool. The idea behind scholarometer --- crowdsourcing scholarly data --- was presented at the Web Science 2010 Conference in Raleigh, North Carolina, along with some promising preliminary results. Recently acquired functionality includes a Chrome version, percentile calculations for all impact measures, export of bibliographic data in variou…
-

Menczer comments on real-time search in IEEE Spectrum
The IEEE Spectrum piece Real-Time Search Stumbles Out of the Gate discusses the recent integration of real-time search features, such as Twitter and other microblog entries, into major search engines. Professor Filippo Menczer, CNetS associate director, comments in the article on the challenges posed by real-time search. Here is an excerpt of the interview: IU’s Menczer suggests that with all this…
-

Folks in Folksonomies at WSDM 2010
Fil will present the paper Folks in folksonomies: Social link prediction from shared metadata (authored with Rossano Schifanella, Alain Barrat, Ciro Cattuto, and Ben Markines) at WSDM 2010 in New York on February 5. The paper discusses homophily, or more specifically the relationship between social connections and social tagging in folksonomies. We show that social similarity measures based on ann…
-

Ruj Akavipat earns PhD
Dr. Ruj Congratulations to Ruj — er, Dr. Akavipat who successfully defended his dissertations on reputation systems for peer search networks, earning his PhD!
-
CNetS team shows new levels of refinement in predicting human mobility, epidemic spread
The interplay of human mobility patterns like those between local metropolitan commuters and long-range airline travelers during a global epidemic can be modeled in such detail so as to offer refined views of epidemics that could aid in public health emergency decision making, according to new research published by Professor Alessandro Vespignani's research team at Indiana University. The findings…
-
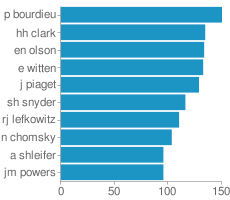
Press discusses social tool to study scholarly impact
Impact metrics based on user queries CNetS graduate student Diep Thi Hoang and associate director Filippo Menczer have developed a tool (called Scholarometer, previously Tenurometer in beta version) for evaluating the impact of scholars in their field. Scholarometer uses the h-index, which combines the scholarly output with the influence of the work, but adds the universal h-index propo…
-

Professor Vespignani will give a talk on planning for H1N1 flu during the Physics and Astronomy Open House on October 31st
Professor Vespignani Alessandro Vespignani, Professor of Informatics, Associate Director of the Pervasive Technology Institute Digital Science Center and Director of the Center for Complex Networks and Systems Research (CNetS) will give a talk on how physics and computers are working together to fight global pandemics like the H1N1 flu virus at the Indiana University Open…
-

Abolish Conference Proceedings
The November 2009 issue of CACM published my letter to the editor entitled Abolish Conference Proceedings (Digital Edition). Here is the published text (which was edited for brevity from my longer letter). As program chair of an ACM conference (Hypertext 2009), I agree with both Lance Fortnow's Viewpoint "Time for Computer Science to Grow Up" (Aug. 2009) and Moshe Vardi's Editor's Letter "Conferen…
-
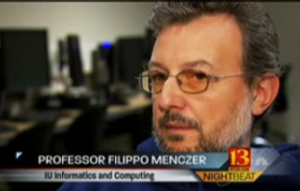
CNetS researchers comment on Twitter
Channel 13 video A report on the popularity of Twitter at IU (which ranks among the top 10 universities on a number of metrics) has sparked some interest in the local media about work CNetS researchers are going on Twitter usage. An interview with Filippo Menczer, associate director of CNetS, appeared on the front page of the Herald-Times on Oct 16, 2009. Indianapolis NBC affiliate Chan…
-

Bringing H1N1 vaccine is a race against time says Professor Vespignani
Professor Vespignani speaks on H1N1 vaccine As Hoosiers roll up their sleeves to take the seasonal flu shots, researchers state that the H1N1 vaccination may take longer to arrive for large scale inoculation than anticipated. "It's a race against time," said IU School of Informatics professor Dr. Alessandro Vespignani who was on his way to an H1N1 conference Tuesday. He s…
-

Vespignani on Board of New Journal of Computational Science
Alessandro Vespignani, an associate director of the Pervasive Technology Institute Digital Science Center and director of the Center for Complex Networks and Systems Research (CNetS) will serve on the editorial board of the new Journal of Computational Science (JoCS). JoCS is an Elsevier Science Journal for novel results in computational science edited by P.M.A. Sloot. The journal aims to be an …
-

CNetS members Beer and Sporns are among IU cognitive scientists who received $3.1 million for innovative training methods
Cognitive scientists at Indiana University Bloomington received a five-year, $3.1 million grant from the National Science Foundation to create and employ innovative methods for training future scientists. According to the NSF, the Integrative Graduate Education and Research Traineeship (IGERT) program is intended to "catalyze a cultural change in graduate education" with innovative new models for …
-
Technology on way to forecasting humanity's needs, Vespignani reports in Science
Much as meteorologists predict the path and intensity of hurricanes, CNetS' Alessandro Vespignani believes we will one day predict with unprecedented foresight, specificity and scale such things as the economic and social effects of billions of new Internet users in China and India, or the exact location and number of airline flights to cancel around the world in order to halt the spread of a pand…
-

Congratulations Ben and Le-Shin!
Dr. Ben Dr. Le-Shin Congratulations to Ben and Le-Shin --- er, Dr. Markines and Dr. Wu! They both successfully defended their dissertations this summer, earning their PhD!
-

School of Informatics and Computing!
Important changes in the school go into effect July 1, 2009: The IUB part of the school is now named School of Informatics & Computing and we won't have internal departments (CS and Informatics) anymore. Faculty will be organized in three internal, transparent (invisible), anonymous divisions. I chair one of these, internally referred to as divA (we are divA faculty)... Seriously, I hope …
-

NaN's strong presence at HT09
NaN had a strong presence at Hypertext 2009 in Torino: Mark's paper What's in a session: tracking individual behavior on the web was nominated for the Best Paper Award. Heather presented the demo Incentives for social annotation about the prototype Firefox extension for GiveALink.org, and the tagging game. (Heather is also demoing at SIGIR'09 in Boston.) I presented the demo Sixearch.org 2.0 peer…
-
Summer talks in Europe
I gave four invited talks in Spain, Italy, and Switzerland this summer: June 18: Social similarity at Yahoo! Labs Barcelona (host: Ricardo Baeza-Yates) --- this is where I got the idea of a foosball table in the lab... June 19: Dynamics of Online Popularity at the University of Barcelona's Department of Fundamental Physics (host: Marian Boguna) June 25: Social similarity at DEI, Politecnico di Mi…
-
Anatomy of a Pandemic: Vespignani on the Science Channel
It’s a terrifying word. But what does it really mean? The outbreak of H1N1 is the latest deadly global battle between man and virus. As we learn more about how viruses mutate, an international effort is underway to vanquish humanity’s most lethal foes. CNetS’ Alessandro Vespignani to appear on Science Channel program about the “global battle between man and virus”.
-

Hypertext 2009
Fil Menczer is one of the organizers of Hypertext 2009, the 20th ACM Conference on Hypertext an Hypermedia. The conference will be held June 29-July 1 at the Villa Gualino Convention Centre, on the hills overlooking Torino, Italy. Hypertext is the main venue for high quality peer-reviewed research on "linking." The Web, the Semantic Web, the Web 2.0, and Social Networks are all manifestations of t…
-

Informatics team finds simple rules that explain universal laws of written text
Similarity Cloud for 'mac' vs 'pc' Alessandro Flammini and Filippo Menczer, along with M. Ángeles Serrano from the University of Barcelona, have authored a paper entitled “Modeling Statistical Properties of Written Text” that has been published in the PLoS One. The paper introduces and validates a generative model that explains from simple rules the simultaneous emergence …
-
NaN abstract for Le-Shin's defense alpha
As adaptive peer network systems becoming an increasingly important development in Web search technology, in this research, an alternative model for peer based Web search is introduced to address the scale problem of centralized search engines. Queries are first matched against the local engine, and then routed to neighbor peers to obtain more results. Initially the network has a random topology (…
-

Paper in Internet Mathematics
The paper On local estimations of PageRank: A mean field approach with Santo Fortunato, Marian Boguna and Sandro Flammini has finally appeared in the journal Internet Mathematics. It is an extended version of “Approximating PageRank from in-degree” presented at WAW2006.
-
NaN talk for May 5, 2009: Mark Meiss, pre-Alpha Thesis Defense
This week at NaN I'll be running through a very preliminary version of my thesis talk, "Structural Mining of Large-Scale Behavioral Data from the Internet," which is all about the things you can discover using network flow data and Web clicks. The big things that I'll be looking to get as feedback have to do with organization and pruning -- I'm not terribly confident of the order in which I prese…
-
Swine flu: Statistical model predicts spread in US, worldwide
GLEaM is a Global Epidemic and Mobility modeler that integrates sociodemographic and population mobility data in spatially structured stochastic disease models to simulate the spread of epidemics at the worldwide scale. The GLEaM team and its PI, Alex Vespignani, have been featured in many news reports about projections of the spread of H1N1 (Mexican flu). Read more about GLEaM…
-
NaN abstract for Alejandro's Defense Alpha
Online documents provide a rich information resource for aiding the generation of concept-map-based knowledge models, but analyzing resources to select concepts and links is a time consuming task. This work focuses on harnessing the information in unstructured text documents using text mining algorithms to generate preliminary concept maps automatically. These maps can be used to assist human us…
-
NaN Abstract for Michael Conover's April 21st Talk
"The problem with Wikipedia is that it only works in practice. In theory, it can never work." -- Zeroeth Law of Wikipedia One of the most important social and intellectual phenomena of the 21st century, the collaboratively-edited online encyclopedia Wikipedia is vexing in its ability to produce informative articles on a multitude of subjects. Leveraging graph theoretic techniques to measure the …
-
NaN abstract for Jacob's April 21st talk
I will talk about some work related to to the problem of predicting the popularity of online content, and some initial results from my experiments in this area. More in detail, I'll overview work by Leskovec et al and Huberman et al on modeling and predicting growth, then outline the results of two initial experiments.
-
Ruj's Alpha Defense
I'm presenting my pre-defense content of my research. There will also be cakes!
-

Spotting the Patterns that Information Makes
Research and Creativity Activity profiles research by CNetS faculty Filippo Menczer and Alessandro Vespignani and their groups in a special issue on networks.
-
AIRWEB 2009 practice talk for Tuesday, 3/24
Dear NaNers, I will be using Tuesday (3/24) as a practice talk for AIRWEB 2009. Hope everyone had a nice spring break! Title: Social Spam Detection Abstract: The popularity of social bookmarking sites has made them prime targets for spammers. Many of these systems require an administrator's time and energy to manually filter or remove spam. Here we discuss the motivations ofsocial spam, and pre…
-

Alex Vespignani named a Fellow in the American Physical Society
Alex Vespignani CNetS Professor Alex Vespignani has been elected to fellowship in the American Physical Society, the preeminent organization of physicists in the United States. Vespignani was honored for his contribution to the statistical physics of complex networks, in particular his seminal work on the spreading of viruses in real networks. More...
-

NSF award to fund research on the social Web
Fil Menczer recently received a $500,000 grant from the National Science Foundation to investigate the Social Integration of Semantic Annotation Networks for Web Applications. The project brings together complex networks and Web mining techniques to develop a new generation of search engines and collaborative Web applications such as GiveALink.org. The researchers will leverage existing annotatio…
-
City road networks grow like biological systems
New Scientist profiles work by Alessandro Flammini on historical development of roadways. Also See press release.
-
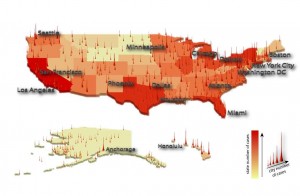
$1.2 million NIH project will help track and predict epidemics
The National Institutes of Health has given $1.2 million to Indiana University researchers to build the ultimate international epidemic research tool. Principle investigators Katy Börner, Steven J. Sherman and Alessandro Vespignani will oversee the project, EpiC, which they hope will make the sharing and re-using of epidemics datasets and algorithms as easy as sharing videos via YouTube. The three…
-
Lagrange Prizes to Arthur, Sinai, Ball
On Friday, April 18 the ISI Foundation and CRT Foundation announced the winners of the First Lagrange Prize: Brian Arthur and Yakov Sinai for their contributions to the science of complex systems, and Philip Ball for his contributions to the promotion of complexity as a popular science writer. The award ceremony took place in the gorgeous Stupinigi Royal Hunting Palace. In the photo, Brian Ar…
-

Hypertext 2008
Ciro Cattuto and I co-chair the social linking track at HT08, the ACM Conference on Hypertext and Hypermedia, which will take place in Pittsburgh in June. Our track received many quality submissions and the technical program is shaping up to be very interesting. Bernardo Huberman will also surely deliver an exciting keynote. Registration is now open! P.S. Congratulations to Ben, Heather, Justin, a…
-
Talks: Torino, Padova, Genova, Roma
This sabbatical is providing wonderful opportunities for me to present our work and establish/strengthen collaborations with several groups in Italy. Recently I have given invited seminars on social search at the Department of Informatics at the University of Torino (hosts Matteo Sereno and Mino Anglano) and on Web traffic at the Department of Math at the University of Padova (host Massimo Marchio…
-
Sixearch.org release
Sixearch Le-Shin Wu and Ruj Akavipat have released the latest version (v.0.3) of sixearch.org, formerly known as 6S. This collaborative, social Web search network allows intelligent adaptive agents to collaborate in a peer network whose emergent structure evolves to discover semantic relationships between peer interests and knowledge. A review of the system should appear in a forthcoming sp…
-
Mark’s talk at WSDM, Stanford
Web click traffic analysis at the First International Conference on Web Search and Data Mining (WSDM 2008) on the beautiful Stanford campus. His talk was very well received, as reported in Greg Linden’s blog. The quality of the conference itself was very good, with several excellent presentations. Those I found most interesting were Qiaozhu Mei’s talk on search log entropy, Nick Craswell on c…
-

Seminar and visit in Rome; Pope controversy
I was in Rome to give a talk at the Interdepartmental Seminar on Algorithmics of the Departments of Computer and System Sciences (DIS) and Computer Science (DI) of the Sapienza University of Rome, and also to visit Guido Caldarelli in the Department of Physics. It was a bit strange to walk through the campus and buildings where I studied 20 years ago (and got my “laurea” in Physics in 1990)…
-

Katrina Panovich selected by CRA
Katrina Panovich Katrina Panovich was selected for Honorable Mention in the Computing Research Association's Outstanding Undergraduate Award competition for 2008. Congratulations!
-
CSI Piemonte
No, it’s not an Italian spin-off of the popular TV show. CSI Piemonte is organizing a meeting on Understanding Complexity: a Journey through Science to be held November 22-23 at the Lingotto Convention Center here in Torino. We will have demos and posters on 6S, GiveALink, and the egalitarian effect of search engines. I look forward in particular to seeing my good old friend Dario and my mentor, D…
-
Workshop on Information Networks at ISI
The Workshop on Theoretical Aspects and Models of Large, Complex and Open Information Networks just ended at ISI. There were lots of interesting talks. I presented Mark’s work on the Web click network, and Ben talked about GiveALink. Thanks to the organizers, especially Alain Barrat, as well as the ISI staff for a smooth and fun program!
-
Visit to Yahoo! Research
I just got back from a visit to Yahoo! Research Silicon Valley. I gave two talks presenting our work on social search and web traffic analysis, and met lots of interesting people. They have an amazing group and of course mountains of data to lust after. Hopefully this will lead to collaborations in the future, given the many intersecting research interests.
-

Innovation Award from IBM
We won an IBM UIMA Innovation Award to incorporate UIMA into 6S. An Apache incubator project, the Unstructured Information Management Architecture is an open, industrial-strength platform for unstructured information analysis and search. It will be used to make it easy to develop different semantic search algorithms and deploy them on customized 6S peers. The award will support one graduate stud…
-
Social Phishing
Our study on social phishing in Comm. of the ACM 50(10):94-100, 2007 was one of the most downloaded CACM papers in 2007. It was reported by the Associated Press (picked up by over 100 news sources including Washington Post, LA Times, MSNBC, BusinessWeek, USA Today, Philadelphia Inquirer, Fox News, Forbes, Seattle Post Intelligencer, Miami Herald, San Francisco Chronicle, Denver Post, C…
-
Social Data Mining and Knowledge Building
I will give a talk on social search at the Workshop on Social Data Mining and Knowledge Building, part III of the Mathematics of Knowledge and Search Engines program. The workshop, organized by IPAM, will be held 5–9 November 2007 at UCLA. Joining me as speakers are Luis Rocha and Stan Wasserman from IU and Santo Fortunato and Jose Ramasco from ISI/CNLL. Should be fun!
-
WSDM 2008
Our paper “Ranking Web Sites with Real User Traffic” (by Mark, Fil, Santo, Sandro & Alex) was one of 24 accepted by the First Web Search and Data Mining Conference. WSDM (pronounced “wisdom”) is a brand new ACM conference intended to be complementary to the World Wide Web Conference tracks in search and data mining. With 151 submissions, the acceptance rate was 16%. WSDM 2008 will be held in…
-
4 talks at ECCS 2007
We are giving 4 invited talks at the European Conference on Complex Systems, in Dresden (October 1-5, 2008): Web click traffic network (by Fil) at Complex Networks: Dynamics and Topology Interplay GiveALink (by Ben) at Enhancing Social Interaction: Recommendation Systems, Reputation, P2P, Trust and Social Networks 6S (by Fil) at Enhancing Social Interaction: Recommendation Systems, Reputation…
-

Advances in Artificial Life
New book with the latest advances in Artificial Life. This book, co-edited by Prof. Luis M. Rocha, constitutes the refereed proceedings of the 9th European Conference on Artificial Life, ECAL 2007, held in Lisbon, Portugal, September 2007. The 125 revised full papers presented were carefully reviewed and selected. The papers are organized in topical sections on conceptual articles, morphogenesis a…
-

Mathematical models add more options for life sciences, cancer researchers
The use of mathematical modeling to better understand the origin and progression of life systems is the subject of American Scientist cover article Multiscale Modeling in Biology featuring the work of Prof. Santiago Schnell. A related paper authored by Schnell is ranked first among the Theoretical Biology & Medical Modelling most viewed articles of all time. This is a list of the most frequent…
-
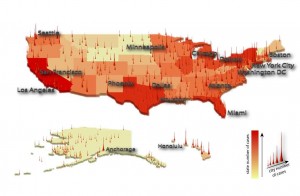
IU team has pulse on pandemic preparation
An Indiana University School of Informatics-led team of researchers have developed a mathematical model that can predict the spread and severity of a worldwide flu outbreak, giving health and public safety officials a leg up on where to dedicate their resources. Their report, published in the journal PLoS Medicine, describes several scenarios of flu virus pandemics and how best to contain them. Th…
-
New institute will benefit tech industries, scientists
Whether scientific or business, structured or unstructured, streaming or static, the need to effectively search for and use data is paramount. That need will be fulfilled at the Data and Search Institute at the Indiana University School of Informatics. Funded by a planning grant from the National Science Foundation Industry/University Cooperation Center program, the institute will speed the flow o…
-
Researchers throttle notion of search engine dominance
Search engines are not biased towards well-known Web sites. In fact, they actually produce an egalitarian effect as to where traffic is directed, say researchers at the Indiana University School of Informatics. Their study, Topical interests and the mitigation of search engine bias, appears in the Aug. 7-11 issue of the Proceedings of the National Academy of Sciences and challenges the “Goog…
-

Integrating artificial life simulation with synthetic biology
Biologists long have focused their microscopes and attention on how the natural world works. Artificial life, in turn, uses complex computing techniques to better understand, visualize and even mimic life’s processes. Now comes an approach that combines science and engineering in order to design and construct novel biological parts, devices and biological systems for useful purposes. It’s called s…
-

Global conference focuses on social, behavioral network sciences
Some of the world’s leading network scientists will soon share their latest research at a conference hosted by Indiana University. NetSci 2006: International Workshop and Conference on Network Science brings together leading researchers and practitioners such as analysts, modeling experts and visualization specialists. Workshop sessions will be May 16-20 at McCormick Creek’s Canyon Inn in Spencer,…
-
Censearchip
CenSEARCHip received intense coverage including in Slashdot, Network World, PhysOrg, IDS, ACM TechNews, Technology News Daily, Computer World, CCNews, ePrairie, PC World, LaboratoryTalk, Search Engine Journal, USA Today, dozens of new sources around the world (including France, Sweden, Norway, Poland, Russia, Italy, Mexico, e…
-
E-mail cluster bombs
Our work on e-mail cluster bombs (IU News Release) was covered by Geek.com, ScienceDaily, Complexity Digest, Ascribe, Hindustan Times, various BizJournals, etc. Radio interviews aired on MPR's Future Tense (listen), WFIU, and KMOX's The Grayson Files.
-
Evolution of document networks
A result linking the evolution of document networks (such as the Web) to textual content was mentioned in New Scientist; the paper appeared in a Sackler Colloquium issue of PNAS on Mapping Knowledge Domains, which received coverage by NSF, ScienceDaily, ACM TechNews, BBC News, etc.
-
Growing And Navigating The Small World Web By Local Content
A PNAS paper on Growing And Navigating The Small World Web By Local Content was announced in press releases by PNAS News and UIowa. A radio interview for the program Science in Action was broadcast by BBC World Service (QuickTime | Flash | MP3). The paper received coverage in Technology Research News, ACM TechNews, Complexity Digest, Insight, @-web, Ascribe, B…
-
-
InfoSpiders
InfoSpiders, MySpiders, and intelligent adaptive crawlers have been covered in Wired, Christian Science Monitor, BotSpot, Business 2.0, Bot News, High Technology Careers Magazine, About.com, TechWeb EETimes, @-web, BusinessAtIowa, SearchEngineWatch.com, etc.